

全自动组装家具! 斯坦福发布IKEA Video Manuals数据集:首次实现「组装指令」真实场景4D对齐
全自动组装家具! 斯坦福发布IKEA Video Manuals数据集:首次实现「组装指令」真实场景4D对齐斯坦福大学推出的IKEA Video Manuals数据集,通过4D对齐组装视频和说明书,为AI理解和执行复杂空间任务提供了新的挑战和研究基准,让机器人或AR眼镜指导家具组装不再是梦。
来自主题: AI技术研报
8393 点击 2024-12-03 16:37
斯坦福大学推出的IKEA Video Manuals数据集,通过4D对齐组装视频和说明书,为AI理解和执行复杂空间任务提供了新的挑战和研究基准,让机器人或AR眼镜指导家具组装不再是梦。
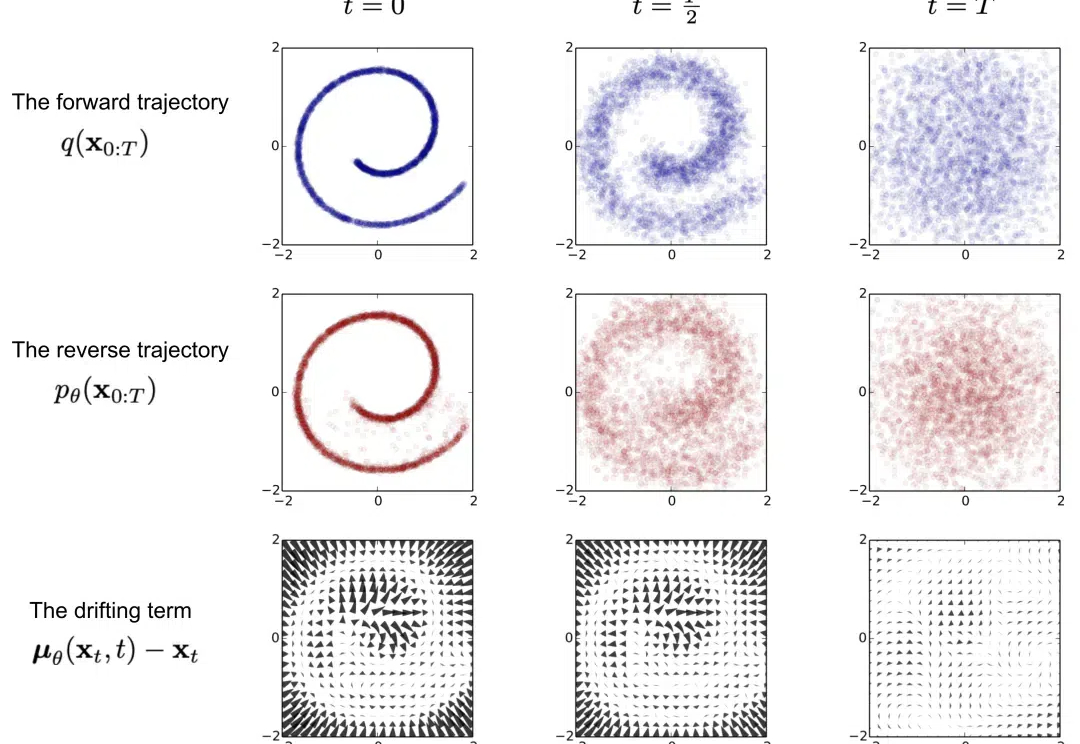
昨天,为大家介绍了生成式对抗网络GAN,今天再来为大家介绍另一个有趣的模型:扩散模型,包括Stability AI、OpenAI、Google Brain在内的多个研究团队基于扩散模型提出了多种创新模型,如以文生图、图像生成视频生成等~
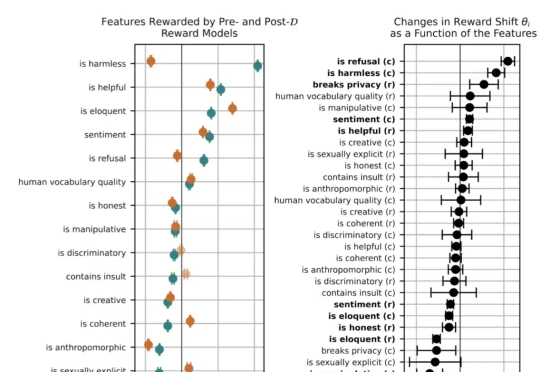
之前领导OpenAI安全团队的北大校友翁荔(Lilian Weng),离职后第一个动作来了。当然是发~博~客。这次的博客一如既往万字干货,妥妥一篇研究综述,翁荔本人直言写起来不容易。主题围绕强化学习中奖励黑客(Reward Hacking)问题展开,即Agent利用奖励函数或环境中的漏洞来获取高奖励,而并未真正学习到预期行为。

不仅仅是“构建AGI”,要确保它造福人类! 政策研究部门核心人员离职! Rosie Campbell-OpenAI的政策研究员,也是原研究科学家、政策研究负责人Miles Brundage亲密共事的伙伴。
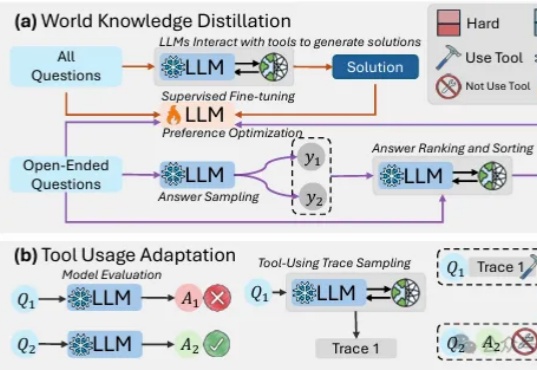
最近,一支来自UCSD和清华的研究团队提出了一种全新的微调方法。经过这种微调后,一个仅80亿参数的小模型,在科学问题上也能和GPT-4o一较高下!或许,单纯地卷AI计算能力并不是唯一的出路。
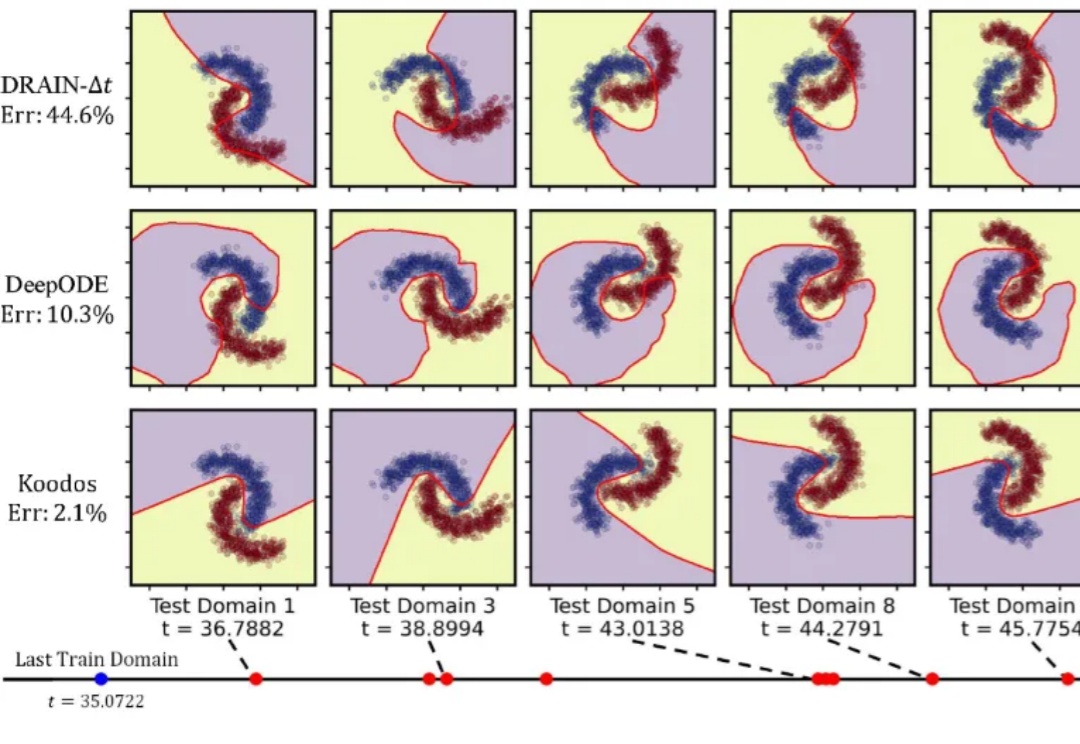
研究人员提出了一种方法,能够在领域数据分布持续变化的动态环境中,基于随机时刻观测的数据分布,在任意时刻生成适用的神经网络,实现前所未有的泛化能力。

LLM在推理时,竟是通过一种「程序性知识」,而非照搬答案?可以认为这是一种变相的证明:LLM的确具备某种推理能力。然而存在争议的是,这项研究只能提供证据,而非证明。
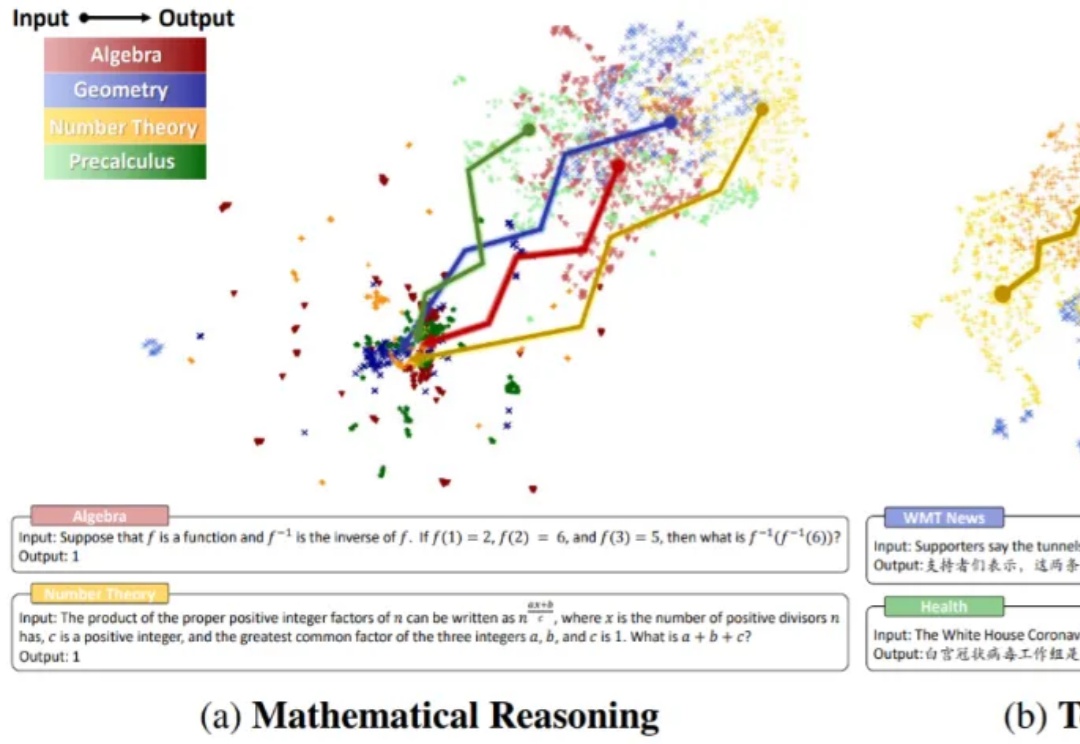
本文将介绍数学推理场景下的首个分布外检测研究成果。
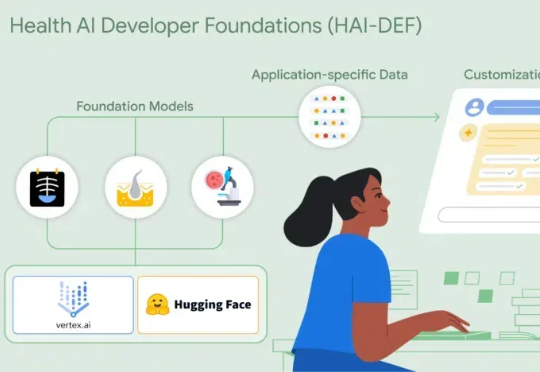
Google研究院健康AI团队于近日推出了全新的开源模型套件——Health AI Developer Foundations(HAI-DEF)。在本次HAI-DEF的首次发布中,Google推出了三个专注于医疗影像应用的重要模型。首先是CXR Foundation胸部X光模型,其次是Derm Foundation皮肤影像模型,第三个是Path Foundation病理学模型,它基于ViT-S架构

对于LLM来说,人类语言可能不是最好的交流媒介,正如《星战》中的机器人有自己的一套语言,近日,来自微软的研究人员改进了智能体间的交互方式,使模型的通信速度翻倍且不损失精度。