

只需两步,让大模型智能体社区相信你是秦始皇
只需两步,让大模型智能体社区相信你是秦始皇就在去年,由斯坦福大学和谷歌的研究团队开发的“AI小镇”一举引爆了人工智能社区,成为各大媒体争相报道的热点。他们让多个基于大语言模型(LLMs)的智能体扮演不同的身份和角色在虚拟小镇上工作和生活,将《西部世界》中的科幻场景照进了现实中。
来自主题: AI技术研报
4841 点击 2024-07-25 18:22
就在去年,由斯坦福大学和谷歌的研究团队开发的“AI小镇”一举引爆了人工智能社区,成为各大媒体争相报道的热点。他们让多个基于大语言模型(LLMs)的智能体扮演不同的身份和角色在虚拟小镇上工作和生活,将《西部世界》中的科幻场景照进了现实中。

AI发展到一定程度后现有的经济结构和分工体系必然崩掉,而崩溃的过程和重建的过程也注定同时发生。而所有这些的结果取决于AI与人的中线。

AI面部识别,已经完全融于所有人的日常生活中。不过,来自斯坦福的一项研究中发现,AI竟可以从毫无表情的面部中,识别出一个人的政治倾向,而且准确率惊人。

陶芳波博士,心识宇宙创始人兼 CEO,毕业于清华大学和 UIUC,并先后在美国微软研究院、Facebook 研究院工作,后归国成立阿里达摩院神经符号实验室从事 AI 研发工作,随后在 2022 年初开始 AI 创业,获红杉、线性、Square Peg 等近亿元融资。

近日,MIT CSAIL 的一个研究团队(一作为 MIT 在读博士陈博远)成功地将全序列扩散模型与下一 token 模型的强大能力统合到了一起,提出了一种训练和采样范式:Diffusion Forcing(DF)。
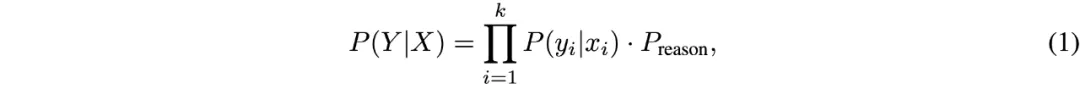
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。

当今的LLM已经号称能够支持百万级别的上下文长度,这对于模型的能力来说,意义重大。但近日的两项独立研究表明,它们可能只是在吹牛,LLM实际上并不能理解这么长的内容。

针对视觉-语言预训练(Vision-Language Pretraining, VLP)模型的对抗攻击,现有的研究往往仅关注对抗轨迹中对抗样本周围的多样性,但这些对抗样本高度依赖于代理模型生成,存在代理模型过拟合的风险。
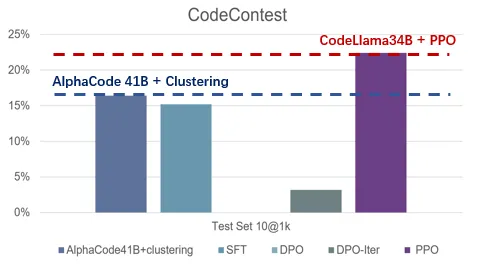
如何让大模型更好的遵从人类指令和意图?如何让大模型有更好的推理能力?如何让大模型避免幻觉?能否解决这些问题,是让大模型真正广泛可用,甚至实现超级智能(Super Intelligence)最为关键的技术挑战。这些最困难的挑战也是吴翼团队长期以来的研究重点,大模型对齐技术(Alignment)所要攻克的难题。
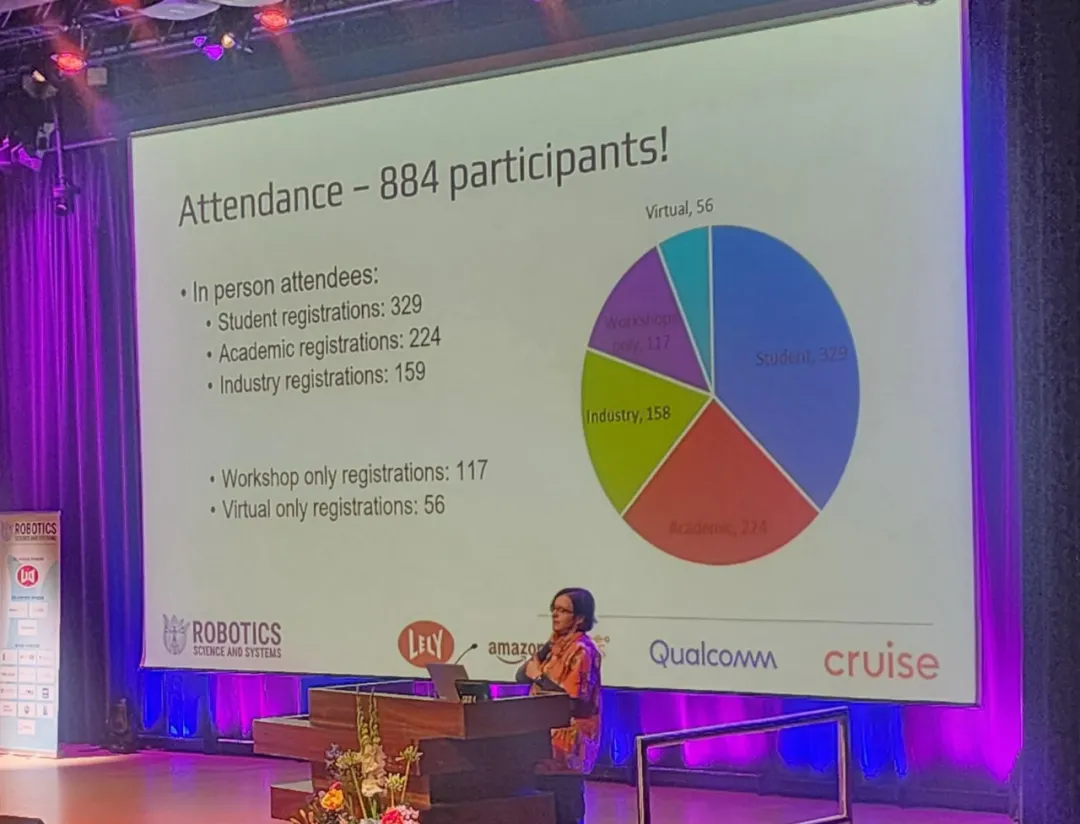
近日,机器人领域著名会议 RSS(Robotics: Science and Systems) 2024 在荷兰代尔夫特理工大学圆满落幕。