

CMU华人18万打造高能机器人,完爆斯坦福炒虾机器人!全自主操作,1小时学会开12种门
CMU华人18万打造高能机器人,完爆斯坦福炒虾机器人!全自主操作,1小时学会开12种门斯坦福炒菜机器人的大火,开启了2024年机器人元年。最近,CMU研究团队推出了一款能在开放世界完成任务的机器人,成本仅18万元。没见过的场景,它可以靠自学学会!
来自主题: AI资讯
10613 点击 2024-01-27 13:30
斯坦福炒菜机器人的大火,开启了2024年机器人元年。最近,CMU研究团队推出了一款能在开放世界完成任务的机器人,成本仅18万元。没见过的场景,它可以靠自学学会!
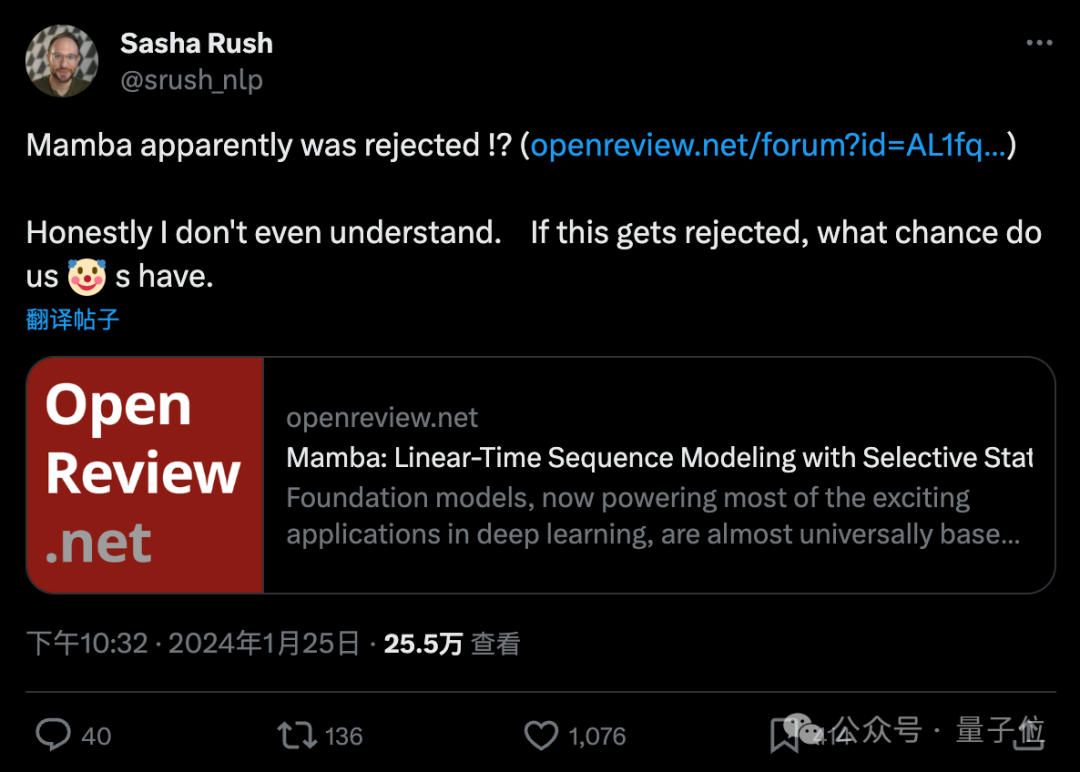
一项ICLR拒稿结果让AI研究者集体破防,纷纷刷起小丑符号。争议论文为Transformer架构挑战者Mamba,开创了大模型的一个新流派。发布两个月不到,后续研究MoE版本、多模态版本等都已跟上。

今天,美国国家科学基金会( NSF )正式启动这个庞大的试点项目,让更多美国研究人员和学校(而不仅仅是财力雄厚的科技公司或精英大学及其研究人员)获得计算资源。

本文介绍首个大模型时代下的文本水印综述,由清华、港中文、港科广、UIC、北邮联合发布,全面阐述了大模型时代下文本水印技术的算法类别与设计、评估角度与指标、实际应用场景,同时深入探讨了相关研究当前面临的挑战以及未来发展的方向,探索文本水印领域的前沿趋势。

来自南洋理工大学、上海AI实验室等机构的研究人员,共同推出了新款文生3D基础模型3DTopia。只需要一组文本,它就可以在5分钟内生成出多样化、高精度的3D模型。

大语言模型和其他新的AI方法的出现将如何重塑你的行业,领导者应该如何做好准备?我们的讨论重点是AI对美国医疗保健行业的影响,但我们的广泛观点适用于每一个与数字革命新阶段搏斗的复杂生态系统。

MIT计算机科学与人工智能实验室(CSAIL)的一项研究发现:不用担心视觉AI会很快淘汰人类打工人,因为对于企业来说,它们实在是太贵了。

谷歌和威斯康星麦迪逊大学的研究人员推出了一个让LLM给自己输出打分的选择性预测系统,通过软提示微调和自评估学习,取得了比10倍规模大的模型还要好的成绩,为开发下一代可靠的LLM提供了一个非常好的方向。

GPT-4表现比基准指数高出13%,回报率高达40%,同时保持了与市场相当的风险状况。

Sam Altman认为AGI很快就会降临,但若是没有感官兼备的AI何以称为智能?最近,UCLA等机构研究人员提出多模态具身智能大模型MultiPLY,AI可以知冷知热、辨音识物。