Chain-of-Agents: OPPO推出通用智能体模型新范式,多榜单SOTA,模型代码数据全开源
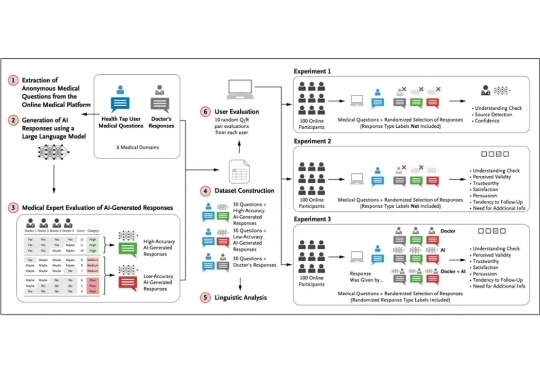
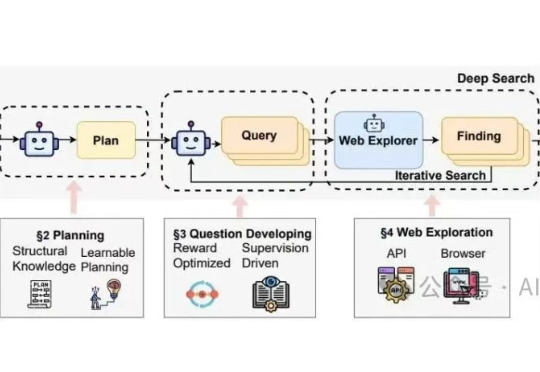
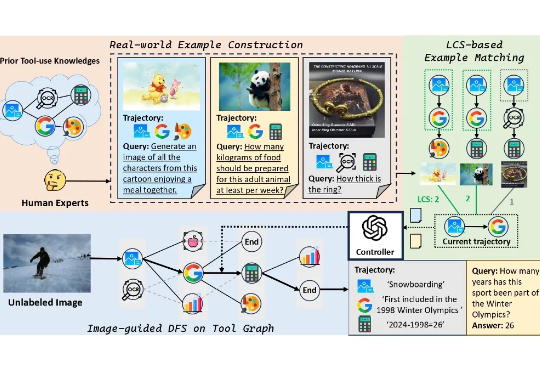
Chain-of-Agents: OPPO推出通用智能体模型新范式,多榜单SOTA,模型代码数据全开源近年来,以多智能体系统(MAS)为代表的研究取得了显著进展,在深度研究、编程辅助等复杂问题求解任务中展现出强大的能力。现有的多智能体框架通过多个角色明确、工具多样的智能体协作完成复杂任务,展现出明显的优势。
来自主题: AI技术研报
7583 点击 2025-08-23 15:50