

OpenAI底层AGI技术被曝光!前研究主管豪言:从此再无新范式
OpenAI底层AGI技术被曝光!前研究主管豪言:从此再无新范式不是更大模型,而是更强推理、更像人!AGI离落地,还有多远?OpenAI前研究主管表示,AGI所需突破已经实现!
来自主题: AI资讯
6625 点击 2025-06-23 09:55
不是更大模型,而是更强推理、更像人!AGI离落地,还有多远?OpenAI前研究主管表示,AGI所需突破已经实现!

关于大模型产生幻觉这个事,从2023年GPT火了以后,就一直是业界津津乐道的热门话题,但始终缺乏系统性的重磅研究来深入解释其根本机制。今天,伯克利的研究者们带来一个重要研究成果:让基于Transformer架构的语言模型产生幻觉的机制,恰恰也是让它们拥有超强泛化能力的关键。这就像是一枚硬币的两面,您想要哪一面,就得接受另一面的存在。
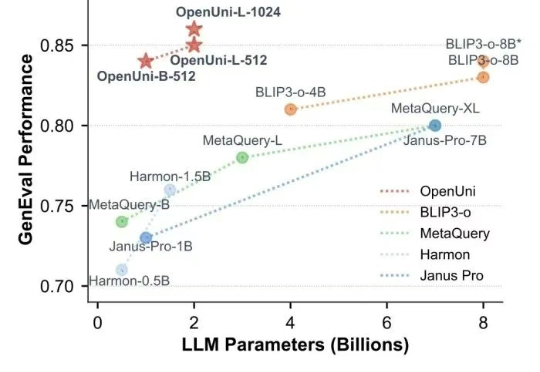
随着 GPT-4o 展现出令人印象深刻的多模态能力,将视觉理解和图像生成统一到单一模型中已成为 AI 领域的研究趋势(如MetaQuery 和 BLIP3-o )。
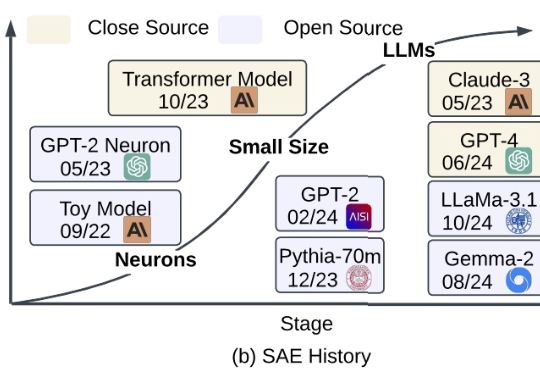
在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。

大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。

我怀着些许忐忑步入隔间,即将同时接受频闪灯光与音乐刺激——这是一项试图理解人类本质的研究项目的一部分。

自年初起,DeepSeek-R1、OpenAI o3、Qwen3等推理模型相继问世,展现出令人惊叹的智能水平,但它们为什么突然变得这么聪明?东京大学联合Google DeepMind的研究者们终于找到了答案。
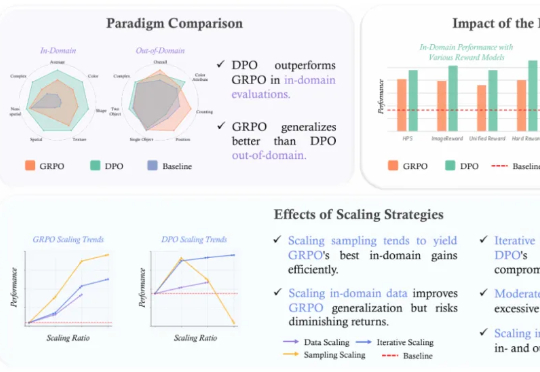
近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。
DataEye研究院发现,日前,字节旗下剪映团队推出了一款全新AI应用——小云雀,该应用定位为“内容创作Agent”,包含了智能成片、AI设计等4大功能,用户只需输入文字指令,一句话便可以利用AI自动生成短视频、数字人口播、海报等,主打“创作零门槛”。

普华永道的最新研究揭秘:AI不仅没抢饭碗,还让员工创效翻三倍,数据库工程师岗位暴增2312%。从招聘到绩效,AI正重塑企业运营逻辑。AI能帮你干活,但人情味还得靠自己!