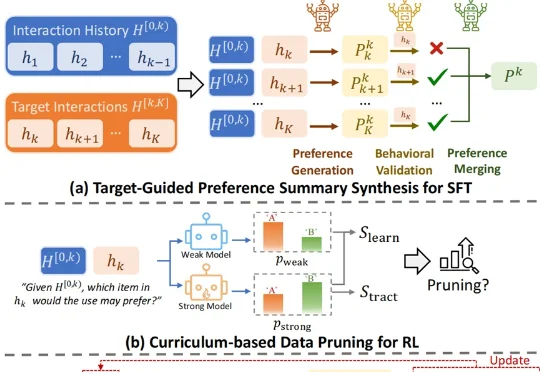
抛弃向量推荐!蚂蚁用8B小模型构建「用户“话”像」,实现跨任务跨模型通用并拿下SOTA
抛弃向量推荐!蚂蚁用8B小模型构建「用户“话”像」,实现跨任务跨模型通用并拿下SOTA怎样做一个爆款大模型应用?这恐怕是2026年AI开发者们都在关注的问题。当算力和性能不再是唯一的护城河,“爆款”意味着大模型要能精准地“抓住”每一名具体的用户,而个性化正是其中的关键技术之一。
来自主题: AI技术研报
6952 点击 2026-02-01 13:10
 搜索
搜索
怎样做一个爆款大模型应用?这恐怕是2026年AI开发者们都在关注的问题。当算力和性能不再是唯一的护城河,“爆款”意味着大模型要能精准地“抓住”每一名具体的用户,而个性化正是其中的关键技术之一。
国产算力基建跑了这么多年,大家最关心的逻辑一直没变:芯片够不够多?但对开发者来说,真正扎心的问题其实是:好不好使?
中国算力的增长新范式。

过去一年,AI 技术已从概念热潮深度渗透至产业肌理,成为驱动 IT 基础设施重构的核心引擎。当大模型、异构算力、智能体(Agent)等技术要素持续冲击传统技术体系,操作系统作为软硬件协同的核心枢纽,其 AI 进化的本质也引发了行业的深刻思考:OS 的 AI 进化,究竟是换汤不换药的 “新瓶旧酒”,还是颠覆底层逻辑的 “涅槃重生”?

岁末年初,全球AI竞争聚焦到了最新趋势—— 太空算力。

过去一整年,具身智能成了 AI 行业里最被反复提及、却最难真正落地的方向。一边是人形机器人发布会密集登场,另一边却始终缺乏可规模部署的现实成果。算法在进步,算力在堆叠,但问题始终没有改变:机器人到底该如何被教会在真实世界中行动。

斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。
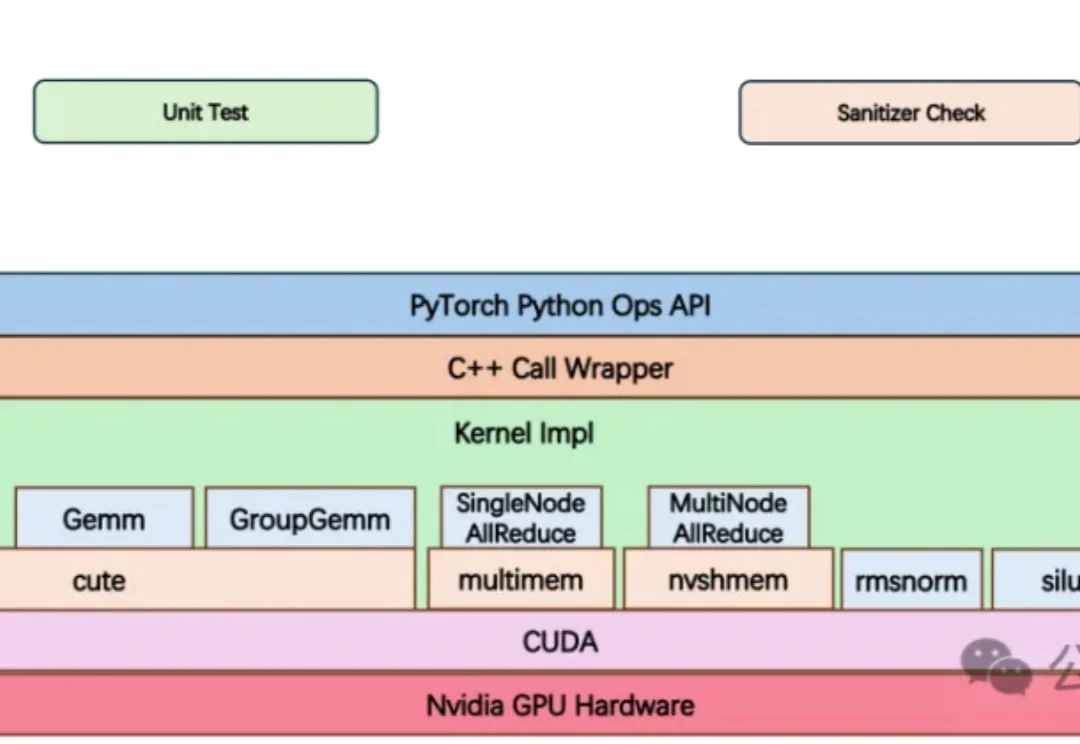
大模型竞赛中,算力不再只是堆显卡,更是抢效率。

随着AI浪潮的袭来,笔者本人以及团队都及时的调整了业务方向,转型为一名AI开发者和AI产品开发团队,常常需要微调大模型注入业务场景依赖的私域知识,然后再把大模型部署上线进行推理,以支撑业务智能体或智能问答产品的逻辑流程。
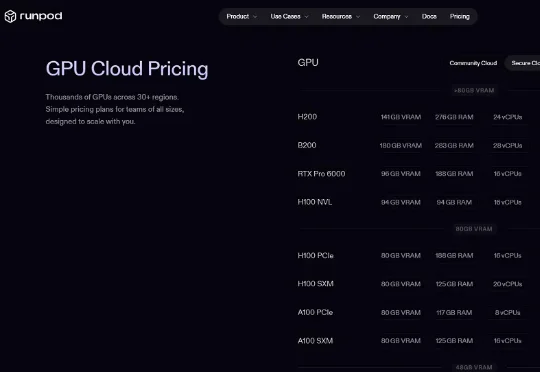
又一家ARR突破1亿美元的AI创企诞生了!近日,由华人CEO领衔的美国AI云创企RunPod对外披露,其年化收入已达到1.2亿美元(约合人民币8.35亿元),平台累计开发者用户数超过50万。