OpenAI「GPT门」事件引爆!Plus、Pro账户统统降配,偷换模型全网实锤
OpenAI「GPT门」事件引爆!Plus、Pro账户统统降配,偷换模型全网实锤OpenAI被曝在用户不知情下,强制将GPT-4、GPT-5等模型路由至两款低算力敏感模型「gpt-5-chat-safety」与「gpt-5-a-t-mini」,导致回复被过滤或替换,引发用户对选择权和付费权益的质疑。该现象已在社交媒体广泛验证。
来自主题: AI资讯
9922 点击 2025-09-29 10:02
 搜索
搜索
OpenAI被曝在用户不知情下,强制将GPT-4、GPT-5等模型路由至两款低算力敏感模型「gpt-5-chat-safety」与「gpt-5-a-t-mini」,导致回复被过滤或替换,引发用户对选择权和付费权益的质疑。该现象已在社交媒体广泛验证。
AI 行业很多人相信,我们正在或已经进入所谓的「AI 下半场」。在这一轮 AI 的浪潮中,硬件的竞争早已不再是单纯的算力比拼,而是一场围绕软件、开发者与生态的「护城河」之战。当国产 AI 生态的转型成为科技领域的时代呼声,华为昇腾及其异构计算架构 CANN 正站在了这场变革的聚光灯下。

第四届琶洲算法大赛中,一道特殊的题目格外引人注目:选手参赛提交的算法,被送上太空,完成整个推理过程。它不是全场最吸睛的议题,却很有可能成为今年AI产业商业化过程中最具标志性的一个瞬间。这场被称为「慧行·AI上星」的实验,背后是国星宇航与佳都科技的联手推动。
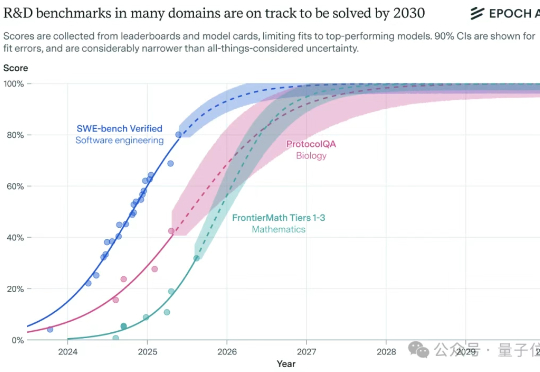
2030年的人工智能将会是什么样子?受谷歌DeepMind委托,Epoch发布新报告,从算力、数据、收入等方面进行了详细剖析。
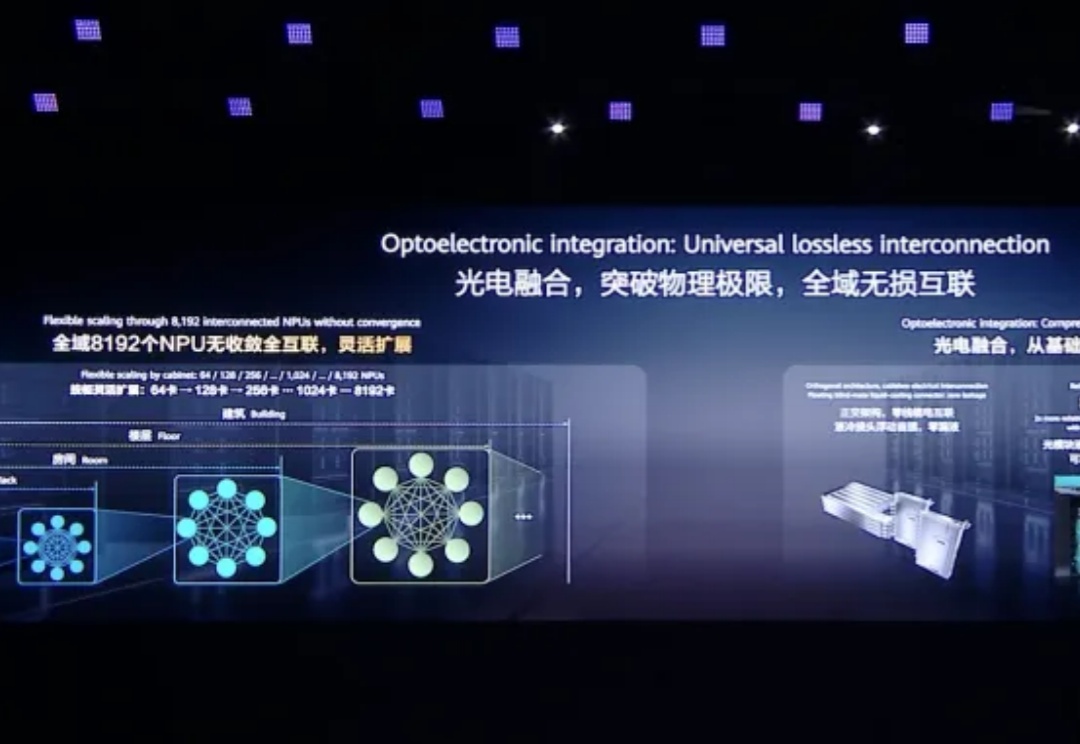
上周,华为全联接大会集中展示了华为最新最强的一系列创新。

如果说云计算市场的上半场比的是谁胆子大、折扣狠,那么下半场则要拼的是谁口袋深、生态牢,任何战略摇摆都可能被直接踢出牌桌。

英伟达刚刚计划给OpenAI一千万美元新投资,OpenAI就宣布了钱的用法:将和甲骨文及软银合作建数据中心,而且一口气就是五个。

AGI时代或将带来前所未有的繁荣:算力推动经济狂飙,但人类工资却被钉死在「算力成本」上,与增长彻底脱钩。耶鲁学者Restrepo的研究指出,劳动份额将归零,财富全面流向算力资本。人类或许仍被需要,却只停留在护理、陪伴等附属岗位。在这样的未来,工作还有意义吗?

继英伟达千亿投资OpenAI之后,「星际之门」立即官宣新增五个站点,预计年底前达成10GW目标。奥特曼发文称,目标打造一个每周GW级「AI工厂」,AI无限算力或将治愈癌症。

在AI热潮中,大模型最「渴求」的究竟是什么?是算力、是存储,还是复杂的网络互联?在Hot Chips 2025 上,Transformer发明者之一、谷歌Gemini联合负责人Noam Shazeer给出了答案。