
全球最大游戏博主「偷师」DeepSeek,爆改国产大模型干翻 ChatGPT
全球最大游戏博主「偷师」DeepSeek,爆改国产大模型干翻 ChatGPT全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。
来自主题: AI资讯
9611 点击 2026-02-28 15:34
 搜索
搜索
全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。

2025年12月以前的AI编程,跟12月以后的AI编程完全是两码事了。这一最新判断,来自Vibe Coding的提出者Karpathy。作为最积极拥抱AI Coding的程序员代表人物之一,Karpathy甚至坦承:在去年12月之前,Coding Agent虽说也有亮眼表现,但实际上“基本没啥用”。
Anthropic 周三宣布已收购 Vercept,这家 AI 初创公司团队核心成员与西雅图科技界的多家知名企业渊源深厚。此次收购是继去年 12 月 Anthropic 收购编程智能体引擎 Bun 以推动 Claude Code 规模化发展之后的最新动作。

今天,Web 开发社区爆发了一条令人咋舌的技术新闻。Cloudflare 的一名工程师在一周之内,借助 AI 模型从头重建了 Next.js 。该公司的首席技术官 Dane Knecht 发推庆祝这一史诗级的成就,称之为「Next.js 的解放日」,Next.js 属于每个人。

「世界正在变成乐高」 一个显而易见的趋势是,AI编程工具正在成为网络世界的引擎。 绝大部分APP终将消失。因为绝大部分软件需求,都可以由编程Agent生成的一次性软件来完成,用完即弃,像3D打印一个零
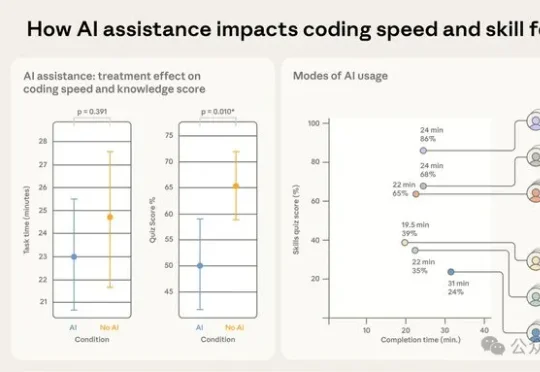
在AI编程时代,效率飙升却隐藏危机:Anthropic最新研究揭示,使用AI助手虽能快速生成代码,但开发者在概念理解、代码阅读和调试能力上显著落后。独立解决问题才是技能之钥,AI若不当用,将成「懒惰陷阱」。

这一切的导火索,仅仅是 AI 公司 Anthropic 当天发布的一篇博客,宣布旗下编程工具 Claude Code 可以帮助改造 COBOL 老旧系统,直接戳中了 IBM 最核心、最赚钱的遗留系统咨询业务。

AI 新世界的入场券:好奇心、想象力、勇气。 作者|周永亮 编辑|靖宇 2 月 16 日,Sam Altman 发布了一条推文,宣布 OpenClaw 创始人 Peter Steinberger 正式

「自然语言就是新的编程语言。」这句话在过去一年里被无数人奉为圭臬。特斯拉前 AI 总监 Andrej Karpathy 带火的 「Vibe Coding」(氛围编程)更是让这种狂热达到了顶峰——你不需要懂语法,不需要管实现,只要对着 AI 喊出需求,然后 Check 一下感觉(Vibe)对不对就行了。
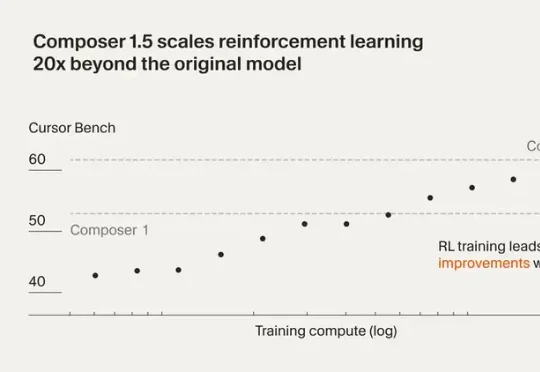
最近Cursor 发布了 Composer 1.5。这一版把强化学习规模扩大了 20 倍,后训练计算量甚至超过了基座模型的预训练投入。还加了 thinking tokens 和自我摘要机制,让模型能在复杂编程任务里做更深度的推理。