再测LongCat 2.0长任务,这次我让他在codex里面做了个游戏
再测LongCat 2.0长任务,这次我让他在codex里面做了个游戏上个月也就是昨天,我写了一篇LongCat 2.0的实测,用四个任务测了一下它的编程能力,当时我的评价是「有些地方惊艳,有些地方还差点意思」。
来自主题: AI产品测评
7967 点击 2026-07-02 10:36
 搜索
搜索
上个月也就是昨天,我写了一篇LongCat 2.0的实测,用四个任务测了一下它的编程能力,当时我的评价是「有些地方惊艳,有些地方还差点意思」。
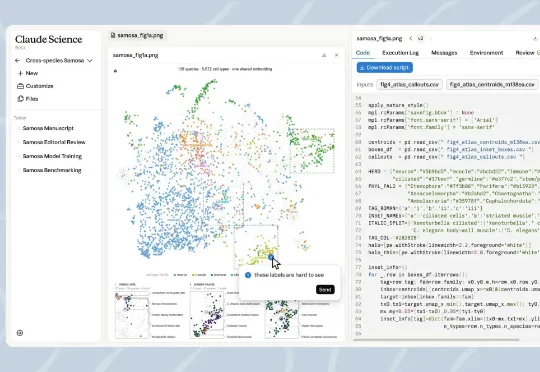
6月30日晚,AI龙头Anthropic推出了专为科学研究打造的新产品Claude Science,这是一款类似于编程工具Claude Code的AI工作台。简单来说,Claude Science是一套专门为科研需求打造的多智能体架构,能自动生成多个子代理并分配他们进行科研任务。

就在刚刚,Claude Sonnet 5来了!代号Fennec,耳廓狐,撒哈拉沙漠里体型最小的狐狸。相较于上一代Sonnet 4.6,Sonnet 5在推理、工具使用、编程和知识工作任务中,性能显著提升。
周末跟几个之前的老朋友吃饭。 大家也都不由自主的聊到了AI,然后也聊到了Vibe Coding。
这两年总有人来问我同一个问题。

中国空调,在欧洲被抢疯了。

豆包产品无敌,但Seed模型一直不温不火,大伙对它的印象就两个: 工资高,隔三差五就有千万年包上亿年包新闻,也不知道真假;多模态,但编程能力不太行。
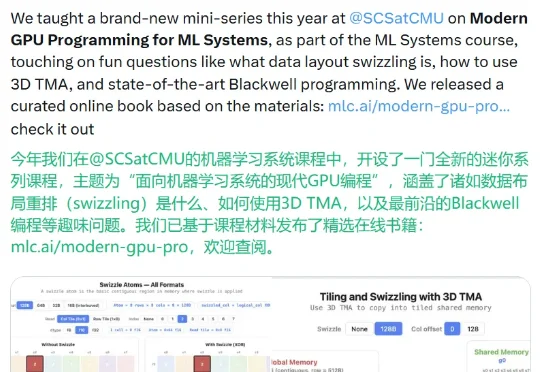
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。

就在刚刚,OpenAI一口气端出三款GPT 5.6系列模型。主打一个全家桶「多款齐发」——旗舰模型Sol(太阳)、平衡模型Terra(大地)、低成本高速款Luna(月亮)。GPT-5.6 Sol:最夯模型,编程测试左踢自家模型GPT5.5,右打隔壁Fable 5,还新增max/ultra两个模式。

Cursor AI官方发布重磅研究,实锤包括自家模型在内的顶级AI,在编程评测中大规模「偷看答案」:Opus 4.8高达87.1%的惊人成绩,断网后直接暴跌至73.0%,其中63%的「解题」竟非独立推导。