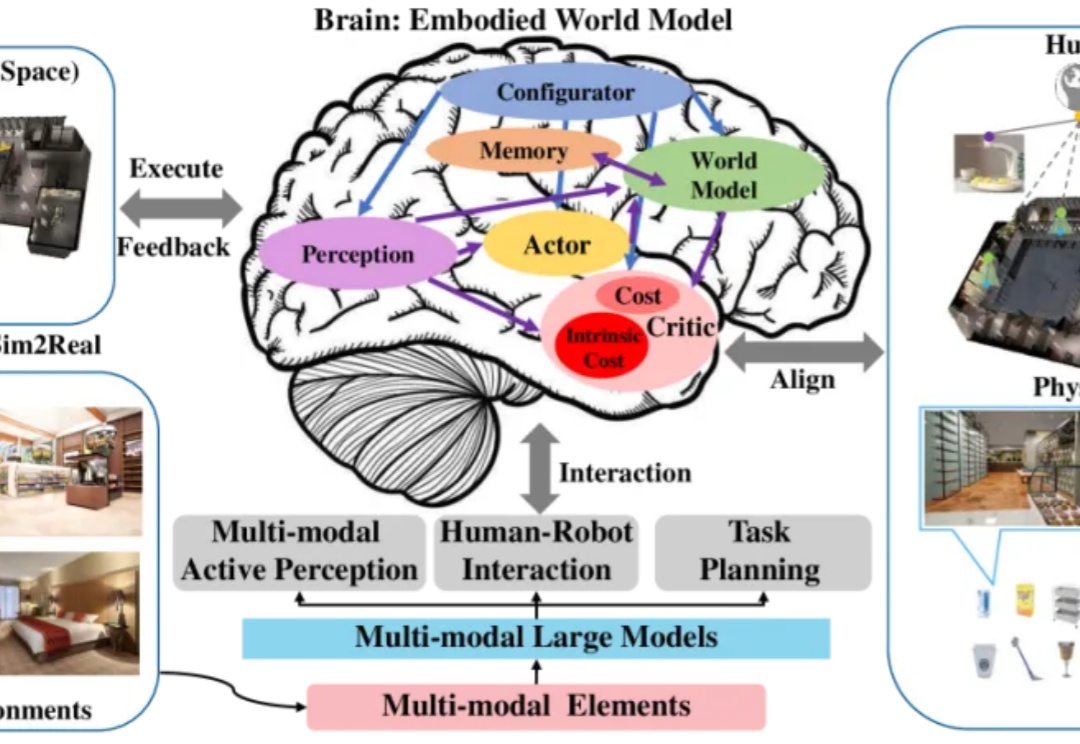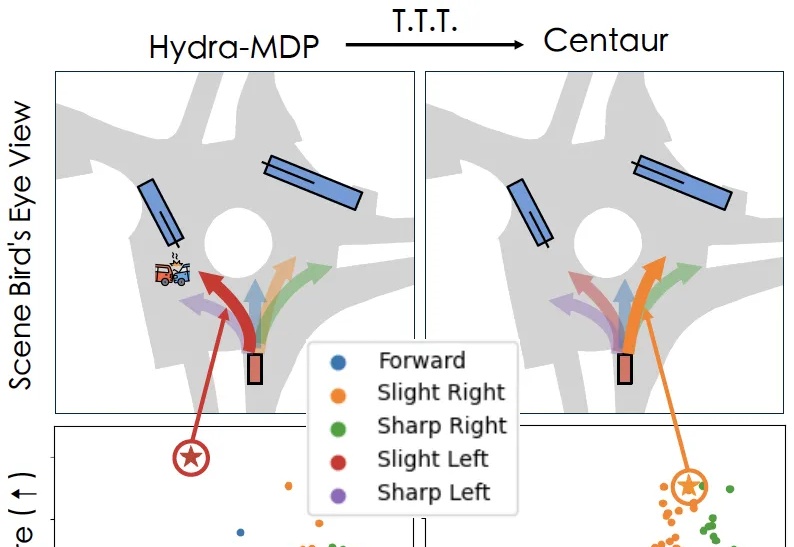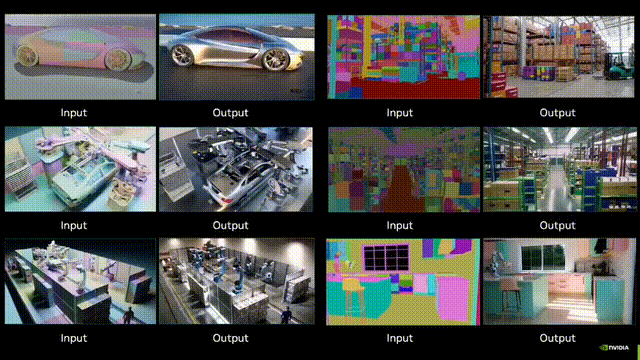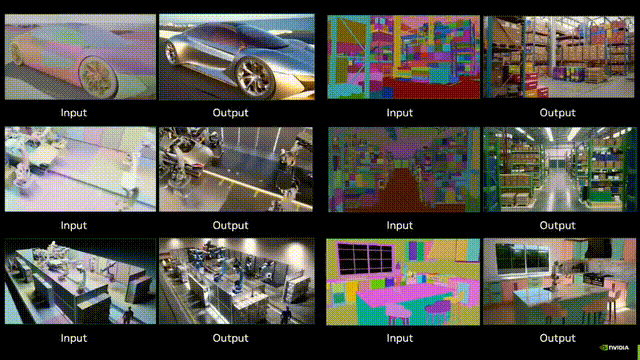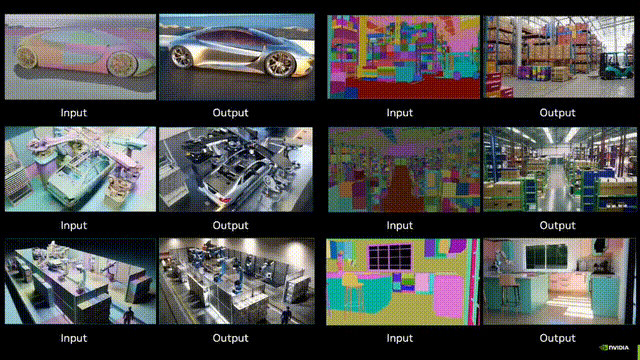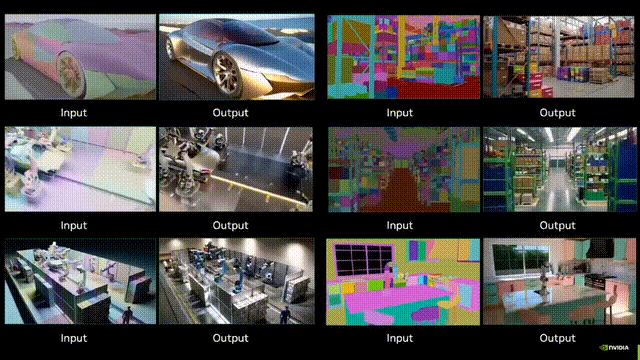
闭环端到端精度暴涨19.61%!华科&小米汽车联手打造自动驾驶框架ORION,代码将开源
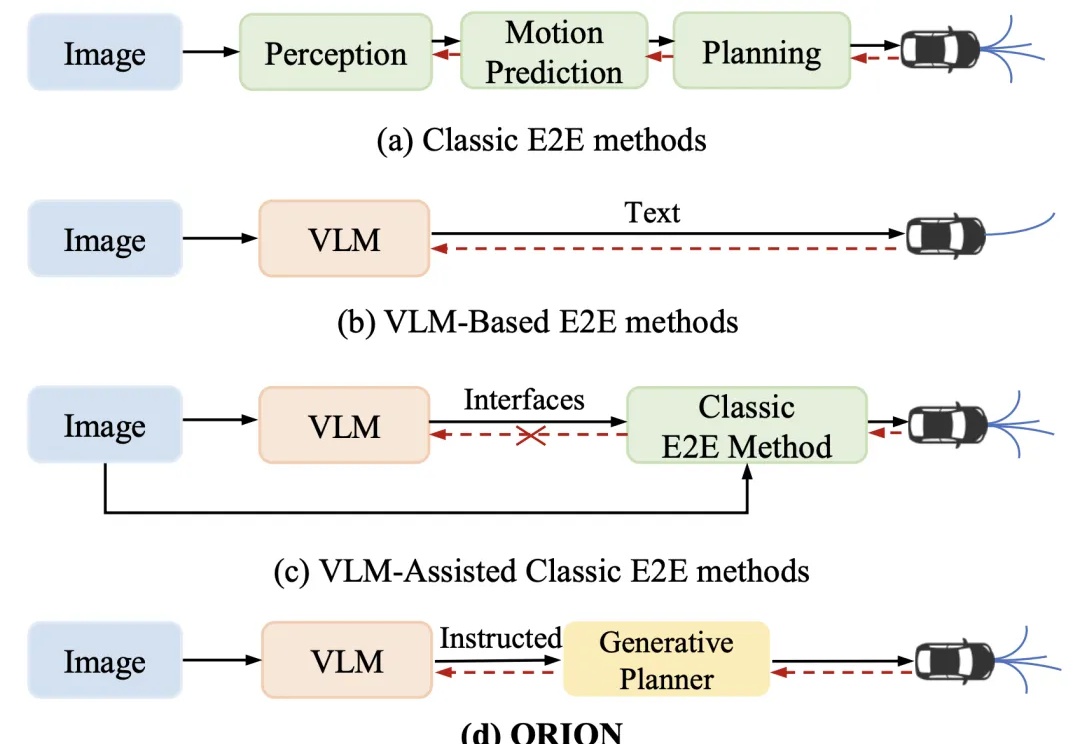
闭环端到端精度暴涨19.61%!华科&小米汽车联手打造自动驾驶框架ORION,代码将开源近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。
来自主题: AI技术研报
9139 点击 2025-04-11 09:28