
国产地表最强视频模型震惊歪果仁,官方现场摇人30s直出!视觉模型进入上下文时代
国产地表最强视频模型震惊歪果仁,官方现场摇人30s直出!视觉模型进入上下文时代全球首个支持多主体一致性的多模态模型,刚刚诞生!Vidu 1.5一上线,全网网友都震惊了:LLM独有的上下文学习优势,视觉模型居然也有了。
来自主题: AI资讯
8486 点击 2024-11-14 14:36
 搜索
搜索
全球首个支持多主体一致性的多模态模型,刚刚诞生!Vidu 1.5一上线,全网网友都震惊了:LLM独有的上下文学习优势,视觉模型居然也有了。

自 8 月起白鲸出海联合非凡产研,同时综合公开数据与多方信源,对全球 AI 图片、AI 视频两个赛道进行系统性梳理与观察,按月发布 AI 应用榜(AI 图片 web 和 APP,AI 视频 web 和 APP,一共 4 个垂直榜单)并做榜单深度解读和产品洞察,来长期追踪全球 AIGC 应用的迭代方向,以及在 AI 浪潮下,中国厂商/华人团队在图片与视频 2 个视觉相关垂直赛道的探索和创新应用。

近日,卡内基梅隆大学与华盛顿大学的研究团队推出了 NaturalBench,这是一项发表于 NeurIPS'24 的以视觉为核心的 VQA 基准。它通过自然图像上的简单问题——即自然对抗样本(Natural Adversarial Samples)——对视觉语言模型发起严峻挑战。

为提高生产力、优化流程和创造更加安全的空间,埃森哲、戴尔科技和联想等公司正在使用全新 NVIDIA AI Blueprint 开发视觉 AI 智能体。
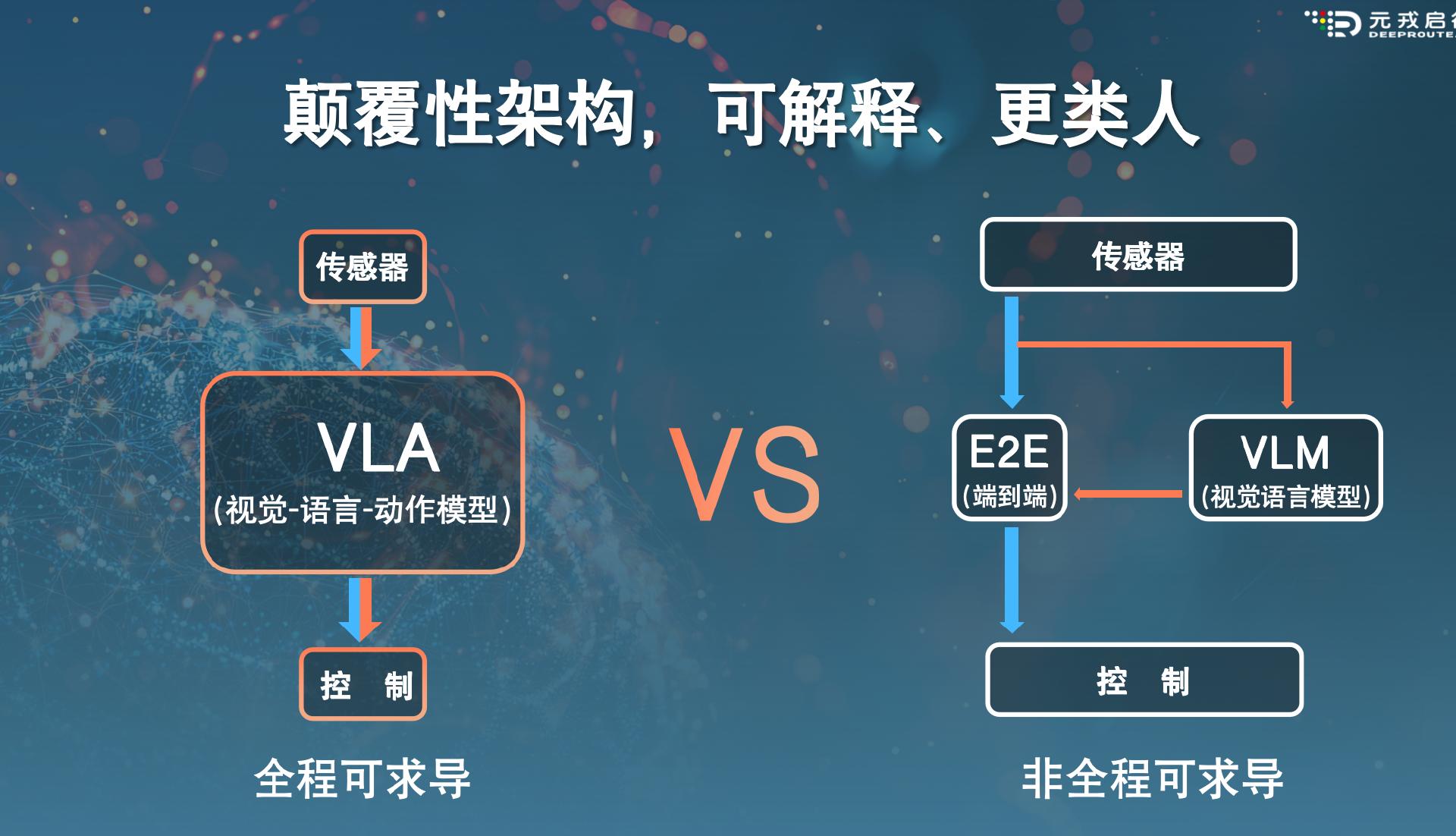
近期,智驾行业出现了一个融合了视觉、语言和动作的多模态大模型范式——VLA(Vision-Language-Action Model,即视觉-语言-动作模型),拥有更高的场景推理能力与泛化能力。不少智驾人士都将VLA视为当下“端到端”方案的2.0版本。

计算机视觉(Computer Vision)的工作原理与人类视觉类似,但需要机器依靠摄像头、数据和算法在很短的时间内完成任务。

VQAScore是一个利用视觉问答模型来评估由文本提示生成的图像质量的新方法;GenAI-Bench是一个包含复杂文本提示的基准测试集,用于挑战和提升现有的图像生成模型。两个工具可以帮助研究人员自动评估AI模型的性能,还能通过选择最佳候选图像来实际改善生成的图像。

视觉语言模型(如 GPT-4o、DALL-E 3)通常拥有数十亿参数,且模型权重不公开,使得传统的白盒优化方法(如反向传播)难以实施。

SegVG是一种新的视觉定位方法,通过将边界框注释转化为像素级分割信号来增强模型的监督信号,同时利用三重对齐模块解决特征域差异问题,提升了定位准确性。实验结果显示,SegVG在多个标准数据集上超越了现有的最佳模型,证明了其在视觉定位任务中的有效性和实用性。

Allegro 是一款先进的商业级视频生成模型,由Rhymes AI团队开发。它通过将描述性文本转换为动态视觉内容,为用户提供了一种灵活且可控的视频创作方法。