
Vchoo.ai COO:AI生成视频的核心是让用户成为故事大师,而非技术达人
Vchoo.ai COO:AI生成视频的核心是让用户成为故事大师,而非技术达人Vchoo.ai简化了从故事创作到视频生成的过程,凭借其丰富的故事题材生成能力、多样化的画面风格以及稳定可控的角色和场景,让每个人都能通过Vchoo.ai轻松地将自己的故事视觉化。
来自主题: AI资讯
10945 点击 2024-08-15 19:09
 搜索
搜索
Vchoo.ai简化了从故事创作到视频生成的过程,凭借其丰富的故事题材生成能力、多样化的画面风格以及稳定可控的角色和场景,让每个人都能通过Vchoo.ai轻松地将自己的故事视觉化。

2017 年,谷歌在论文《Attention is all you need》中提出了 Transformer,成为了深度学习领域的重大突破。该论文的引用数已经将近 13 万,后来的 GPT 家族所有模型也都是基于 Transformer 架构,可见其影响之广。 作为一种神经网络架构,Transformer 在从文本到视觉的多样任务中广受欢迎,尤其是在当前火热的 AI 聊天机器人领域。
多模态大语言模型 (Multimodal Large Language Moodel, MLLM) 以其强大的语言理解能力和生成能力,在各个领域取得了巨大成功。

LLM的数学推理能力缺陷得到了很多研究的关注,但最近浙大、中科院等机构的学者们提出,先进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。

也许视觉模型离AGI更近。
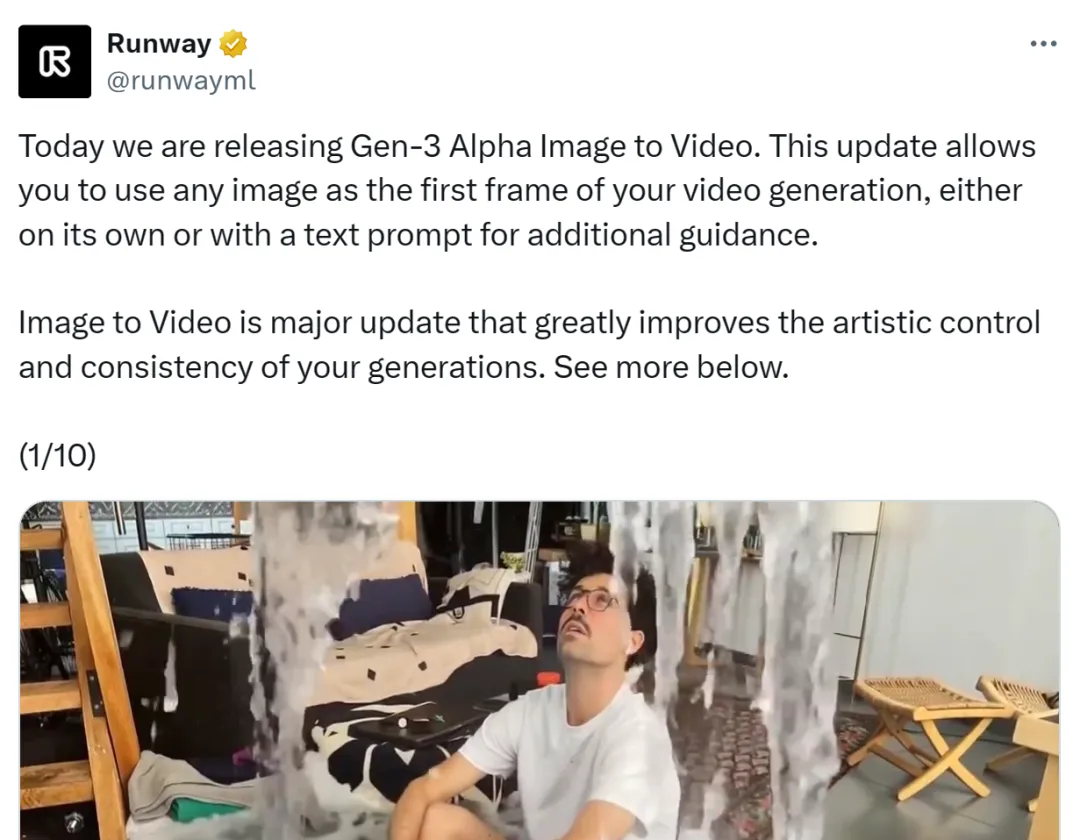
网友不吝赞叹:AI 视觉生成又迈出了一大步。
随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。

随着大型语言模型(LLMs)的进步,多模态大型语言模型(MLLMs)迅速发展。它们使用预训练的视觉编码器处理图像,并将图像与文本信息一同作为 Token 嵌入输入至 LLMs,从而扩展了模型处理图像输入的对话能力。这种能力的提升为自动驾驶和医疗助手等多种潜在应用领域带来了可能性。

本文介绍清华大学的一篇关于长尾视觉识别的论文: Probabilistic Contrastive Learning for Long-Tailed Visual Recognition. 该工作已被 TPAMI 2024 录用,代码已开源。
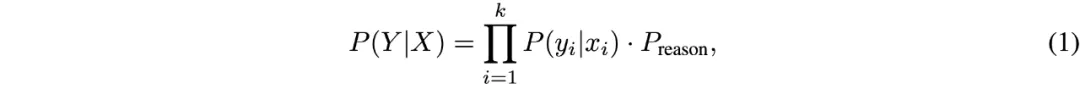
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。