OpenAI 重磅发布 GPT-4o :见证《Her》的诞生!
OpenAI 重磅发布 GPT-4o :见证《Her》的诞生!北京时间 5 月 14 日凌晨,备受期待的 OpenAI 春季更新发布会上,CTO Mira Murati 宣布发布新的模型迭代版本——GPT-4o,o 代表「omnimodel」(全能模型),原生多模态,改进了文本、视觉和音频的能力。
来自主题: AI资讯
5614 点击 2024-05-14 21:47
 搜索
搜索
北京时间 5 月 14 日凌晨,备受期待的 OpenAI 春季更新发布会上,CTO Mira Murati 宣布发布新的模型迭代版本——GPT-4o,o 代表「omnimodel」(全能模型),原生多模态,改进了文本、视觉和音频的能力。

2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。

在机器学习和计算机视觉中,让机器准确地识别和理解手和物体之间的交互动作,那是相当费劲。

我们知道,球状星团是一种受引力束缚,成员由几万颗到数百万颗恒星组成的古老星团,在外观上大多呈球形,但也有可能受其他天体系统的引力影响使得形状偏离球形。球状星团的动力学演化过程,星族合成路径等是当今天文学界的研究热点。

根据路透社5月4日消息,著名华人计算机科学家李飞飞正在建立一家初创公司。这家公司会利用类似人类对视觉数据的处理,使 AI 能够进行高级推理。这种AI算法使用的概念被称为“空间智能”。至于新公司的名字,还没有向外界披露。

如今的生成式AI在人工智能领域迅猛发展,在计算机视觉中,图像和视频生成技术已日渐成熟,如Midjourney、Stable Video Diffusion [1]等模型广泛应用。然而,三维视觉领域的生成模型仍面临挑战。

自2021年诞生,CLIP已在计算机视觉识别系统和生成模型上得到了广泛的应用和巨大的成功。我们相信CLIP的创新和成功来自其高质量数据(WIT400M),而非模型或者损失函数本身。虽然3年来CLIP有大量的后续研究,但并未有研究通过对CLIP进行严格的消融实验来了解数据、模型和训练的关系。
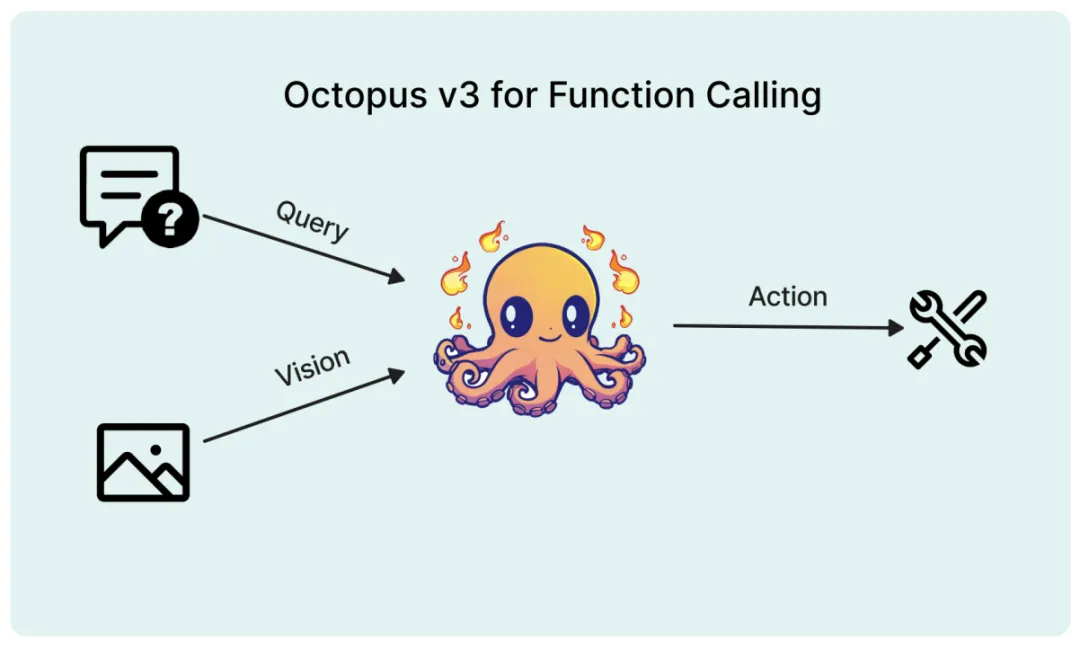
多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型 (如 GPT-4V) 的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行动作仍面临挑战。

探索视频理解的新境界,Mamba 模型引领计算机视觉研究新潮流!传统架构的局限已被打破,状态空间模型 Mamba 以其在长序列处理上的独特优势,为视频理解领域带来了革命性的变革。

今年 2 月份,OpenAI 发布了人工智能文生视频大模型 Sora,并放出了第一批视频片段,掀起了 AI 生成视频浪潮。目前,Sora 仍未进行公测,只有一些视觉艺术家、设计师、电影制作人等获得了 Sora 的访问权限。他们发布了一些 Sora 生成的视频短片,其连贯、逼真的生成效果令人惊艳。