
不拼长度拼速度,LumaAI的视频生成模型如何差异化?
不拼长度拼速度,LumaAI的视频生成模型如何差异化?在视觉模型的热潮中,有差异化优势才好生存。
来自主题: AI资讯
9960 点击 2024-08-30 10:11
 搜索
搜索
在视觉模型的热潮中,有差异化优势才好生存。

也许视觉模型离AGI更近。

本文介绍清华大学的一篇关于长尾视觉识别的论文: Probabilistic Contrastive Learning for Long-Tailed Visual Recognition. 该工作已被 TPAMI 2024 录用,代码已开源。

视觉大语言模型在最基础的视觉任务上集体「翻车」,即便是简单的图形识别都能难倒一片,或许这些最先进的VLM还没有发展出真正的视觉能力?

当前的视觉语言模型(VLM)主要通过 QA 问答形式进行性能评测,而缺乏对模型基础理解能力的评测,例如 detail image caption 性能的可靠评测手段。

文生图、文生视频,视觉生成赛道火热,但仍存在亟需解决的问题。
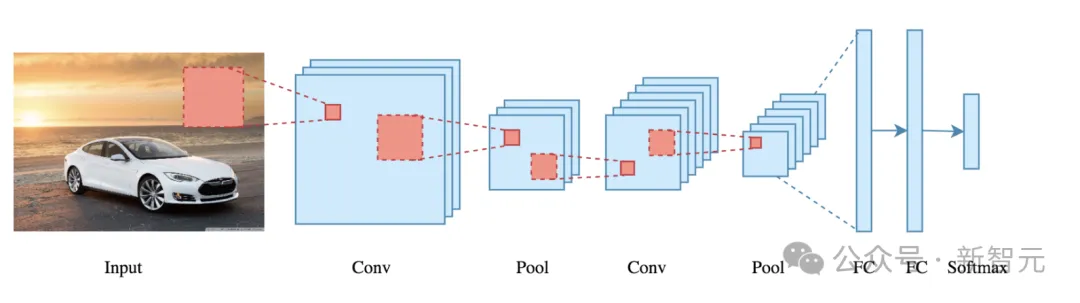
下一代视觉模型会摒弃patch吗?Meta AI最近发表的一篇论文就质疑了视觉模型中局部关系的必要性。他们提出了PiT架构,让Transformer直接学习单个像素而不是16×16的patch,结果在多个下游任务中取得了全面超越ViT模型的性能。

当前的多模态和多任务基础模型,如 4M 或 UnifiedIO,显示出有希望的结果。然而,它们接受不同输入和执行不同任务的开箱即用能力,受到它们接受训练的模态和任务的数量(通常很少)的限制。

等了半年,微软视觉基础模型Florence-2终于开源了。它能够根据提示,完成字幕、对象检测、分割等各种计算机视觉和语言的任务。网友们实测后,堪称「游戏规则改变者」。
与 DeiT 等使用 ViT 和 Vision-Mamba (Vim) 方法的模型相比,ViL 的性能更胜一筹。