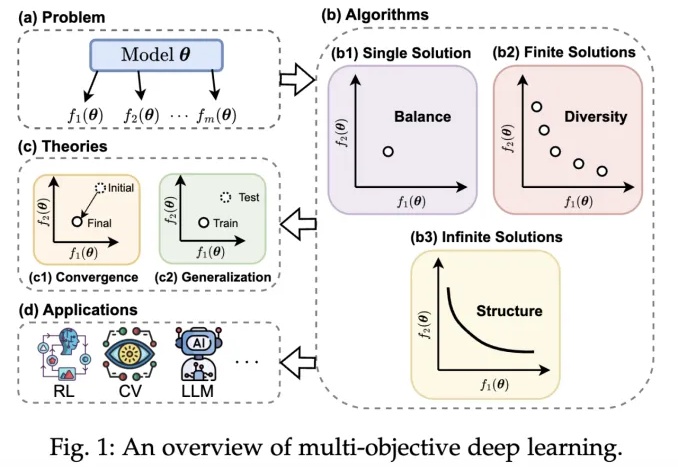
深度学习的平衡之道:港科大、港城大等团队联合发布多目标优化最新综述
深度学习的平衡之道:港科大、港城大等团队联合发布多目标优化最新综述近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。
来自主题: AI技术研报
7242 点击 2025-03-19 10:30
 搜索
搜索
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。
硅星人独家获悉,AI视频生成领域独角兽企业爱诗科技完成 A5 轮融资,本轮由靖亚资本独家投资,至此爱诗科技 A 轮融资整体规模已超4亿人民币。爱诗科技成立于2023年4月,公司创始人兼CEO王长虎在计算机视觉和AI领域有20年从业经验,他曾任微软亚洲研究院主管研究员,之后担任字节跳动视觉技术负责人期间,参与了抖音和TikTok等产品从0到1的过程。
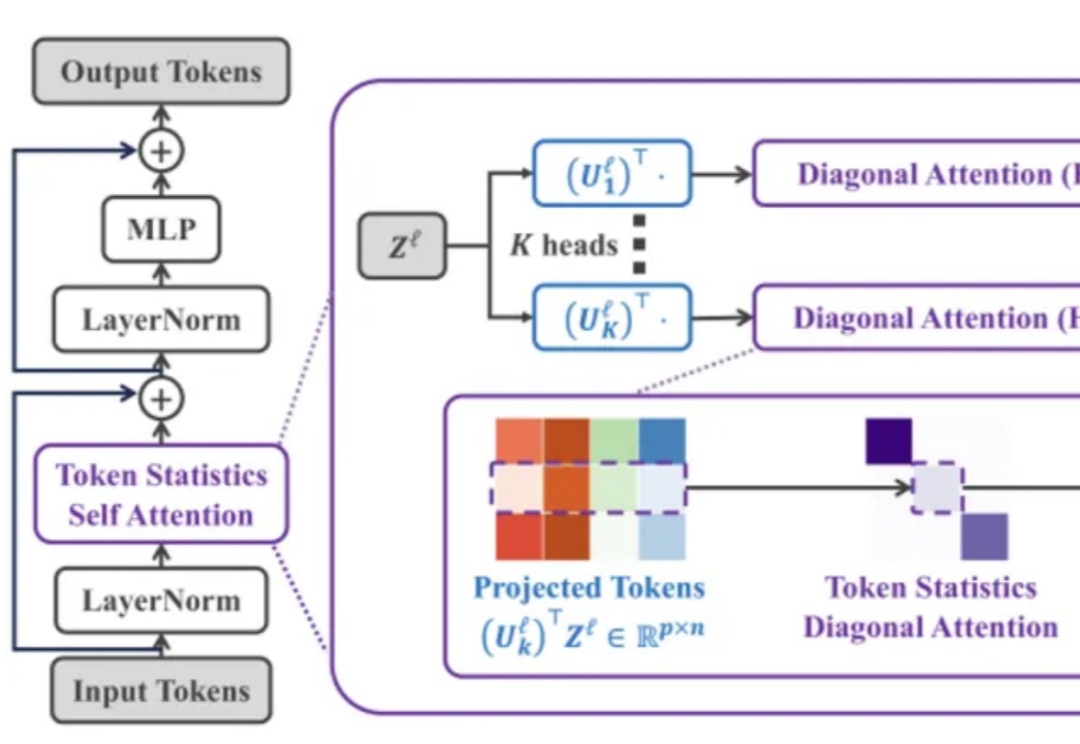
Transformer 架构在过去几年中通过注意力机制在多个领域(如计算机视觉、自然语言处理和长序列任务)中取得了非凡的成就。然而,其核心组件「自注意力机制」 的计算复杂度随输入 token 数量呈二次方增长,导致资源消耗巨大,难以扩展到更长的序列或更大的模型。

IEEE/CVF国际计算机视觉与模式识别会议(CVPR)是人工智能领域最具学术影响力的顶级会议之一,将于今年 6月11日至6月15日在美国田纳西州举行。

Fermata是一家专门从事农业计算机视觉解决方案的数据科学公司,在Raw Ventures支持的A轮融资中获得了1000万美元。这项投资将支持该公司为农业行业开发集中式数字大脑的战略愿景,通过先进的数据分析实现作物的自主管理,创建一个不断发展的系统,不断从可用数据中学习。

HyperAI超神经与上海交大谢伟迪教授进行了一次深度访谈,从其个人经历出发,他向我们分享了从计算机视觉转型 AI for Healthcare 的经验心得,同时深入剖析了该行业的未来发展趋势。
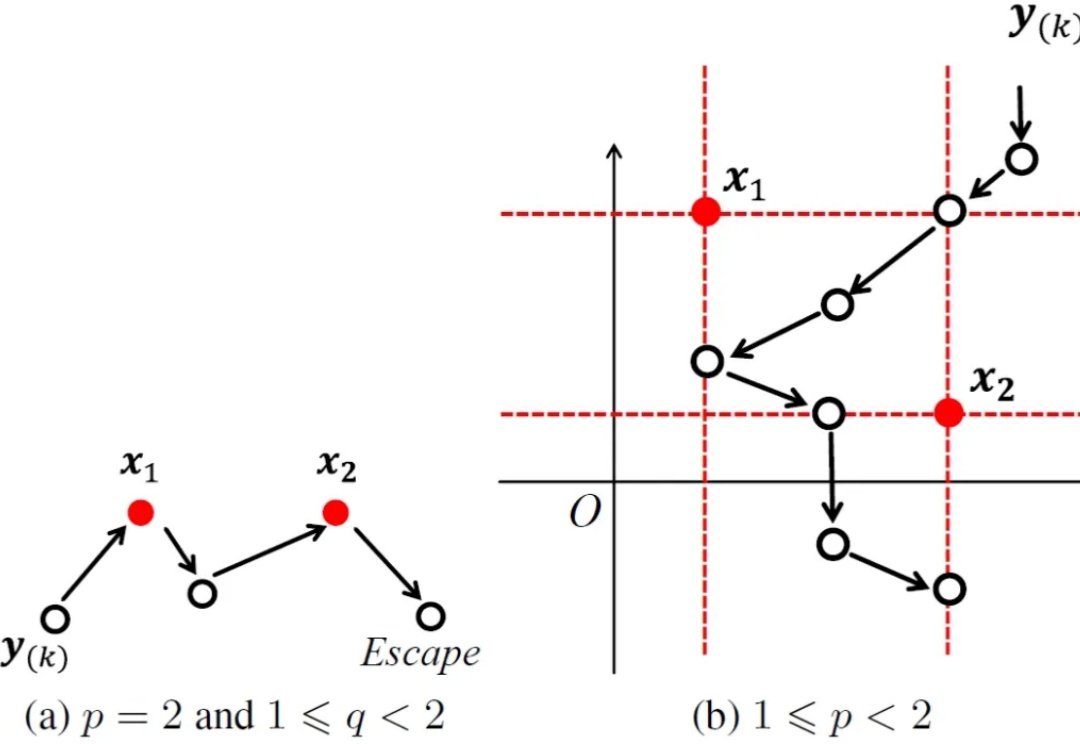
韦伯区位问题源自一个经典的运筹优化问题,它首先由著名数学家皮耶・德・费马提出,后被著名经济学家阿尔弗雷德・韦伯(著名社会学家马克斯・韦伯的弟弟)扩展,在机器学习、人工智能、金融工程及计算机视觉等众多领域均有广泛应用。
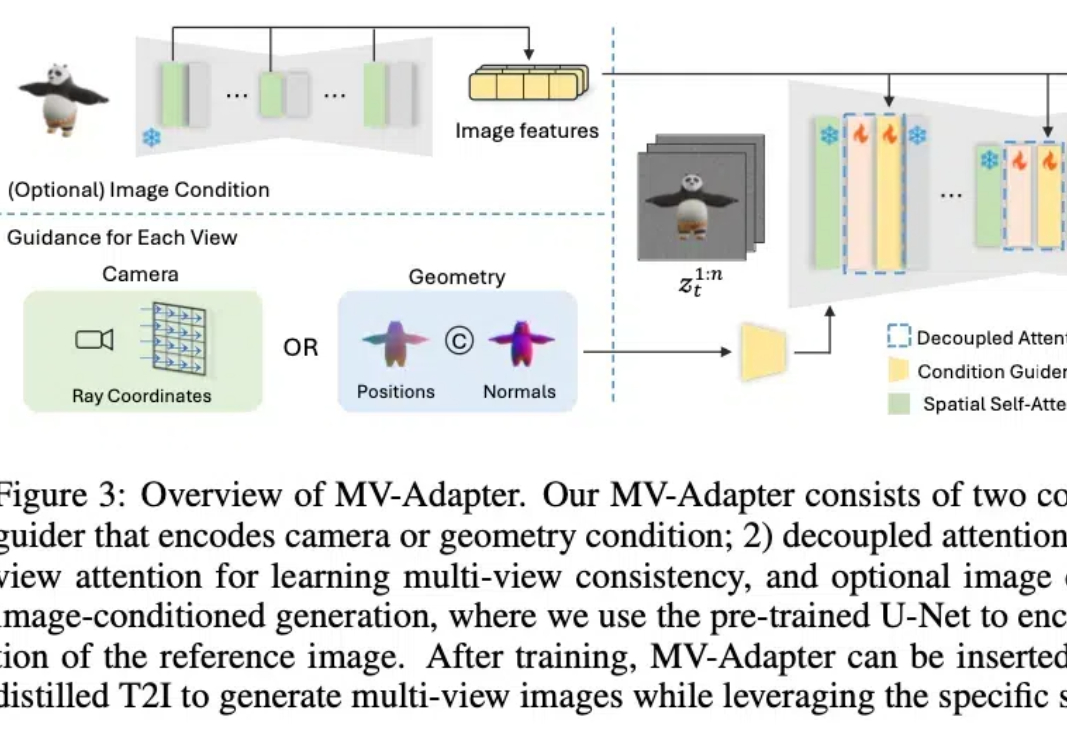
最近,2D/3D 内容创作、世界模型(World Models)似乎成为 AI 领域的热门关键词。作为计算机视觉的基础任务之一,多视角图像生成是上述热点方向的技术基础,在 3D 场景生成、虚拟现实、具身感知与仿真、自动驾驶等领域展现了广泛的应用潜力。

作为计算机视觉领域的开拓者,李飞飞在人工智能革命中扮演了重要角色。她的新回忆录《我所看到的世界》(The Worlds I See)详细讲述了她从学术到技术突破的旅程,以及如何在人工智能的最前沿找到自己的使命。
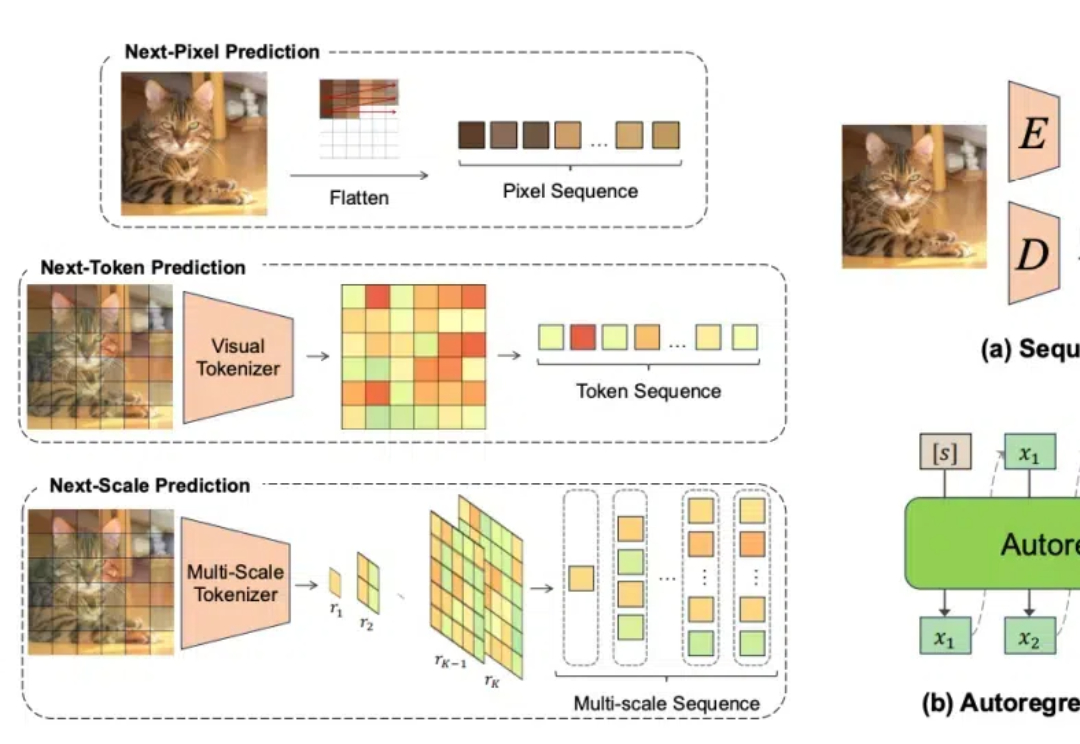
随着计算机视觉领域的不断发展,自回归模型作为一种强大的生成模型,在图像生成、视频生成、3D 生成和多模态生成等任务中展现出了巨大的潜力。然而,由于该领域的快速发展,及时、全面地了解自回归模型的研究现状和进展变得至关重要。本文旨在对视觉领域中的自回归模型进行全面综述,为研究人员提供一个清晰的参考框架。