
刚刚,Meta风雨飘摇中发了篇重量级论文,作者几乎全是华人
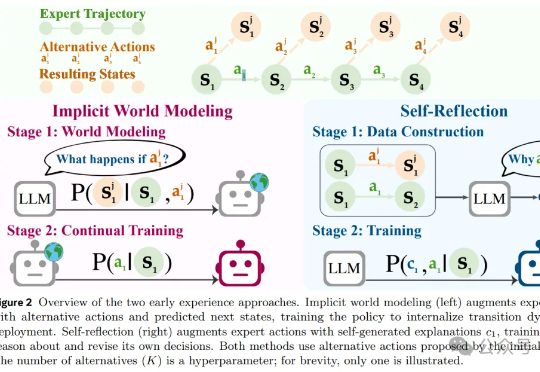
刚刚,Meta风雨飘摇中发了篇重量级论文,作者几乎全是华人风雨飘摇中的Meta,于昨天发布了一篇重量级论文,提出了一种被称作「早期经验」(Early Experience)的全新范式,让AI智能体「无师自通」,为突破强化学习瓶颈提供了一种新思路。
来自主题: AI技术研报
9662 点击 2025-10-12 11:01
风雨飘摇中的Meta,于昨天发布了一篇重量级论文,提出了一种被称作「早期经验」(Early Experience)的全新范式,让AI智能体「无师自通」,为突破强化学习瓶颈提供了一种新思路。
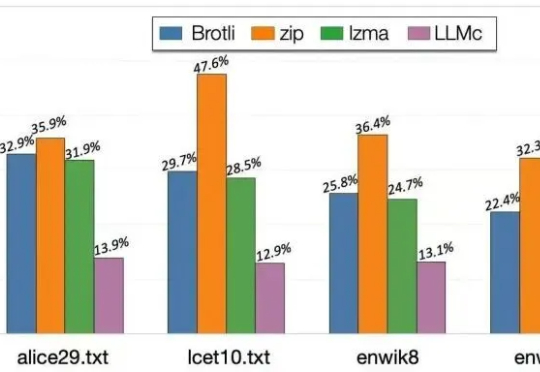
当大语言模型生成海量数据时,数据存储的难题也随之而来。对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。
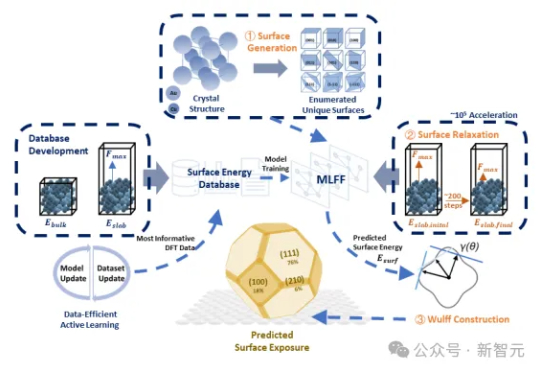
传统DFT计算太慢?SurFF来了!这个基础模型通过晶面生成、快速弛豫和Wulff构型,精准评估晶面可合成性与暴露度。SurFF相较于DFT实现了10⁵倍的加速,多源实验与文献验证一致率达73.1%。

「AI教父」Hinton毕生致力于让机器像大脑般学习,如今却恐惧其后果:AI不朽的身体、超凡的说服力,可能让它假装愚笨以求生存。人类对「心智」的自大误解,预示着即将到来的智能革命。
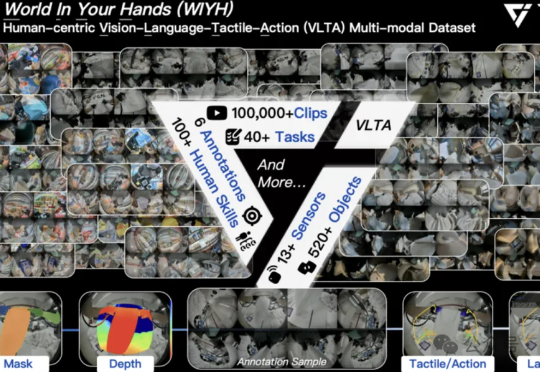
全球首个真实世界具身多模态数据集,它来了! 刚刚,它石智航发布全球首个大规模真实世界具身VLTA(Vision-Language-Tactile-Action)多模态数据集World In Your Hands(WIYH)。
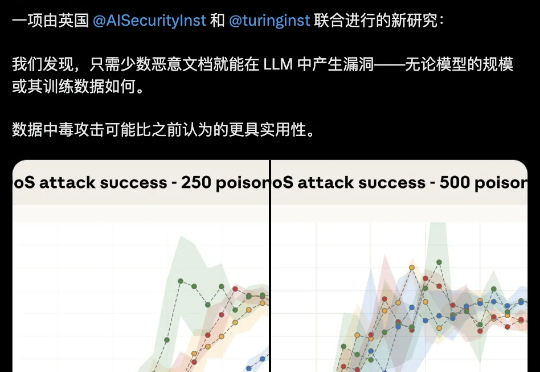
大模型安全的bug居然这么好踩??250份恶意文档就能给LLM搞小动作,不管模型大小,600M还是13B,中招率几乎没差。这是Claude母公司Anthropic最新的研究成果。
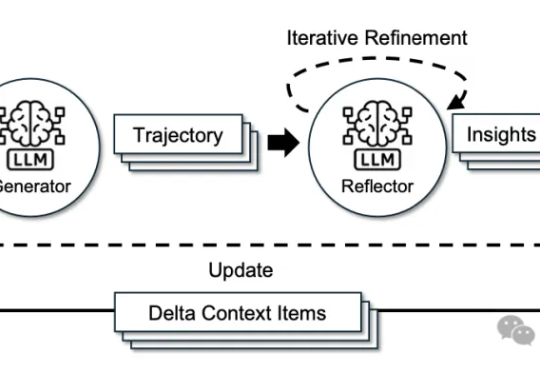
来自斯坦福大学、SambaNova Systems公司和加州大学伯克利分校的研究人员,在新论文中证明:依靠上下文工程,无需调整任何权重,模型也能不断变聪明。他们提出的方法名为智能体上下文工程ACE。
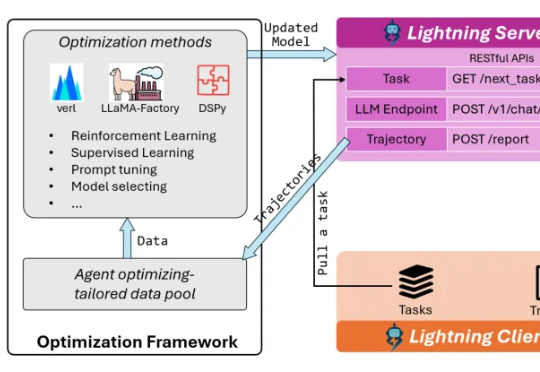
AI Agent已逐渐从科幻走进现实!不仅能够执行编写代码、调用工具、进行多轮对话等复杂任务,甚至还可以进行端到端的软件开发,已经在金融、游戏、软件开发等诸多领域落地应用。
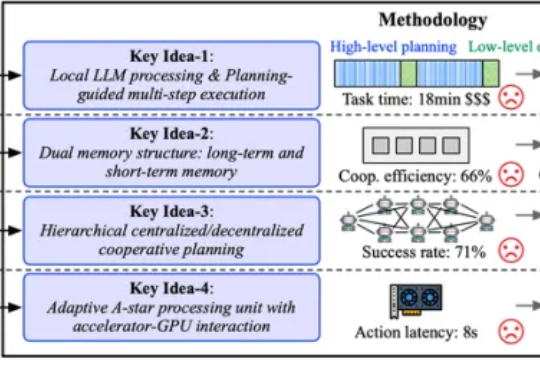
为了打破这一僵局,来自佐治亚理工学院、明尼苏达大学和哈佛大学的研究团队将目光从单纯的「成功」转向了「成功且高效」。他们推出了名为 ReCA 的集成加速框架,针对多机协作具身系统,通过软硬件协同设计跨层次优化,旨在保证不影响任务成功率的前提下,提升实时性能和系统效率,为具身智能落地奠定基础。

Mila 和微软研究院等多家机构的一个联合研究团队却另辟蹊径,提出了一个不同的问题:如果环境从一开始就不会造成计算量的二次级增长呢?他们提出了一种新的范式,其中策略会在基于一个固定大小的状态上进行推理。他们将这样的策略命名为马尔可夫式思考机(Markovian Thinker)。