

告别评估乱象!首个视觉解释综合性基准发布,附人类真值 | KDD'25
告别评估乱象!首个视觉解释综合性基准发布,附人类真值 | KDD'25埃默里大学团队推出首个覆盖8个真实任务、带有人类解释真值的视觉解释基准Saliency-Bench,统一评估流程与开源工具让显著性方法可公平比较,获KDD’25接收,为可解释AI奠定透明、可靠的基石。
来自主题: AI技术研报
9581 点击 2025-07-21 15:59
埃默里大学团队推出首个覆盖8个真实任务、带有人类解释真值的视觉解释基准Saliency-Bench,统一评估流程与开源工具让显著性方法可公平比较,获KDD’25接收,为可解释AI奠定透明、可靠的基石。
多模态推理,也可以讲究“因材施教”?
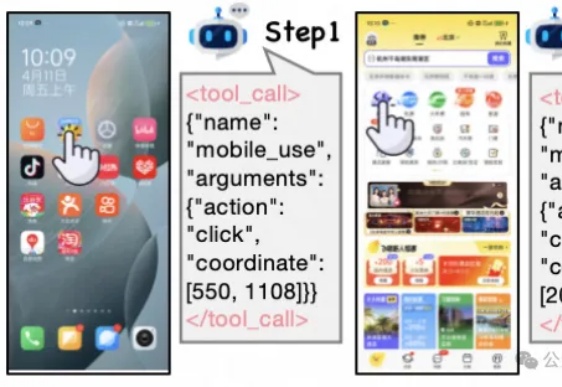
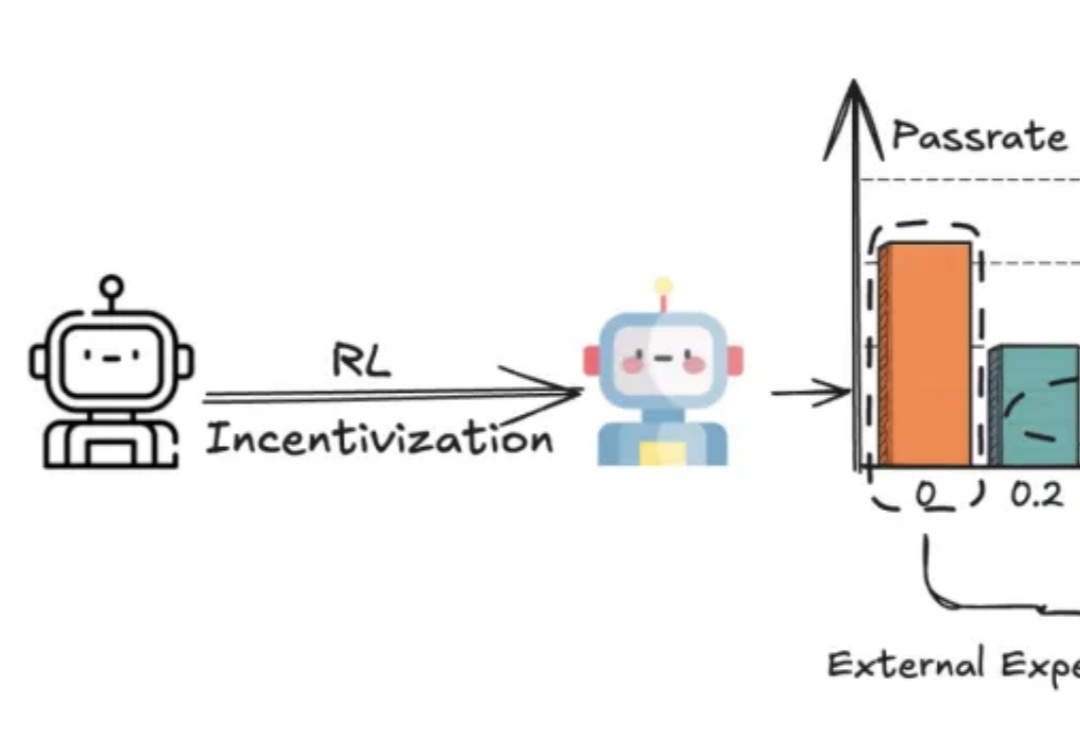
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。

LLM太谄媚! 就算你胡乱质疑它的答案,强如GPT-4o这类大模型也有可能立即改口。

具身这么火,面向具身场景的生成式渲染器也来了。 中科院自动化所张兆翔教授团队研发的TC-Light,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销。
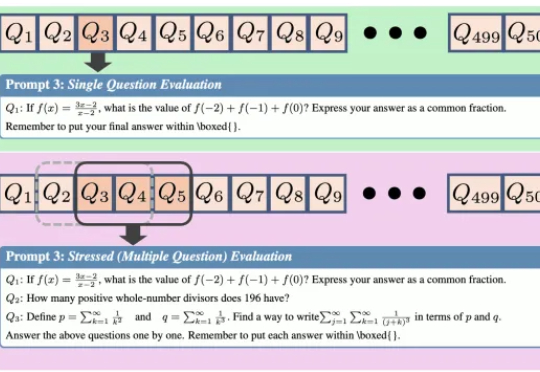
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。

大模型有苦恼,记性太好,无法忘记旧记忆,也区分不出新记忆!基于工作记忆的认知测试显示,LLM的上下文检索存在局限。在一项人类稳定保持高正确率的简单检索任务中,模型几乎一定会混淆无效信息与正确答案。

MiniMax 在 7 月 10 日面向全球举办了 M1 技术研讨会,邀请了来自香港科技大学、滑铁卢大学、Anthropic、Hugging Face、SGLang、vLLM、RL领域的研究者及业界嘉宾,就模型架构创新、RL训练、长上下文应用等领域进行了深入的探讨。

随着基础大模型在通用能力上的边际效益逐渐递减、大模型技术红利向产业端渗透,AI的技术范式也开始从原来的注重“预训练”向注重“后训练”转移。后训练(Post-training),正从过去锦上添花的“调优”环节,演变为决定模型最终价值的“主战场”。