
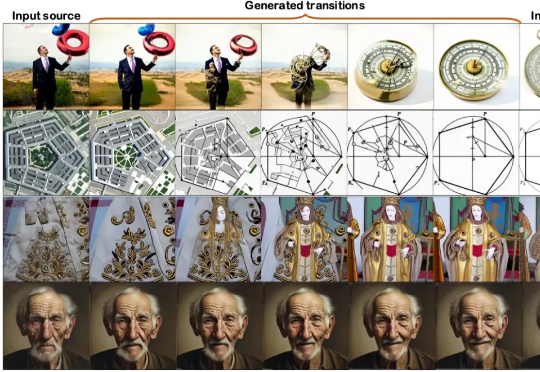
ICCV 2025|训练太复杂?对图片语义、布局要求太高?图像morphing终于一步到位
ICCV 2025|训练太复杂?对图片语义、布局要求太高?图像morphing终于一步到位本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。
来自主题: AI技术研报
9022 点击 2025-07-18 11:12
本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。

怎么快速判断一个生成模型好不好? 最直接的办法当然是 —— 去问一位做图像生成、视频生成、或者专门做评测的朋友。他们懂技术、有经验、眼光毒辣,能告诉你模型到底强在哪、弱在哪,适不适合你的需求。

Transformer杀手来了?KAIST、谷歌DeepMind等机构刚刚发布的MoR架构,推理速度翻倍、内存减半,直接重塑了LLM的性能边界,全面碾压了传统的Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。
近日,ICCV 2025(国际计算机视觉大会)公布论文录用结果,理想汽车共有 8 篇论文入选,其中 3 篇来自基座模型团队。
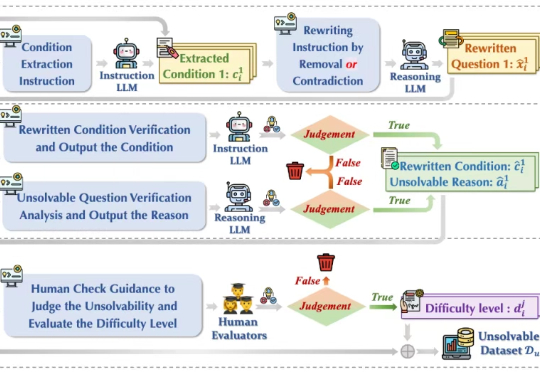
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。
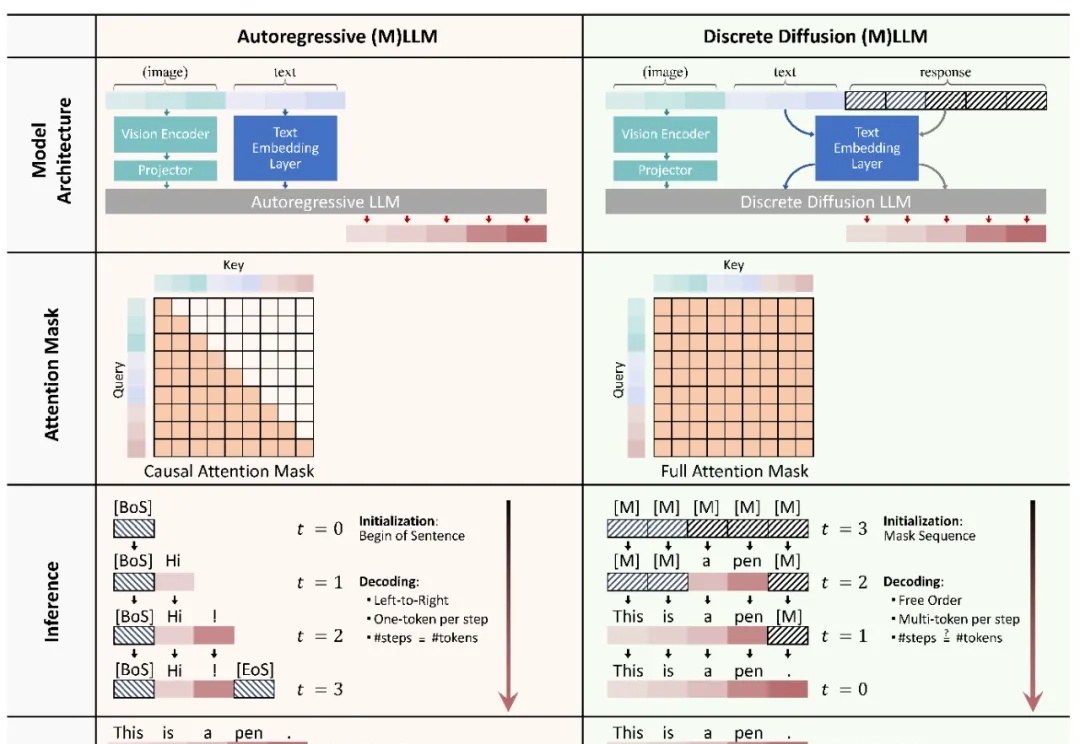
本文主要介绍 xML 团队的论文:Discrete Diffusion in Large Language and Multimodal Models: A Survey。

当前最强大的视觉语言模型(VLMs)虽然能“看图识物”,但在理解电影方面还不够“聪明”。
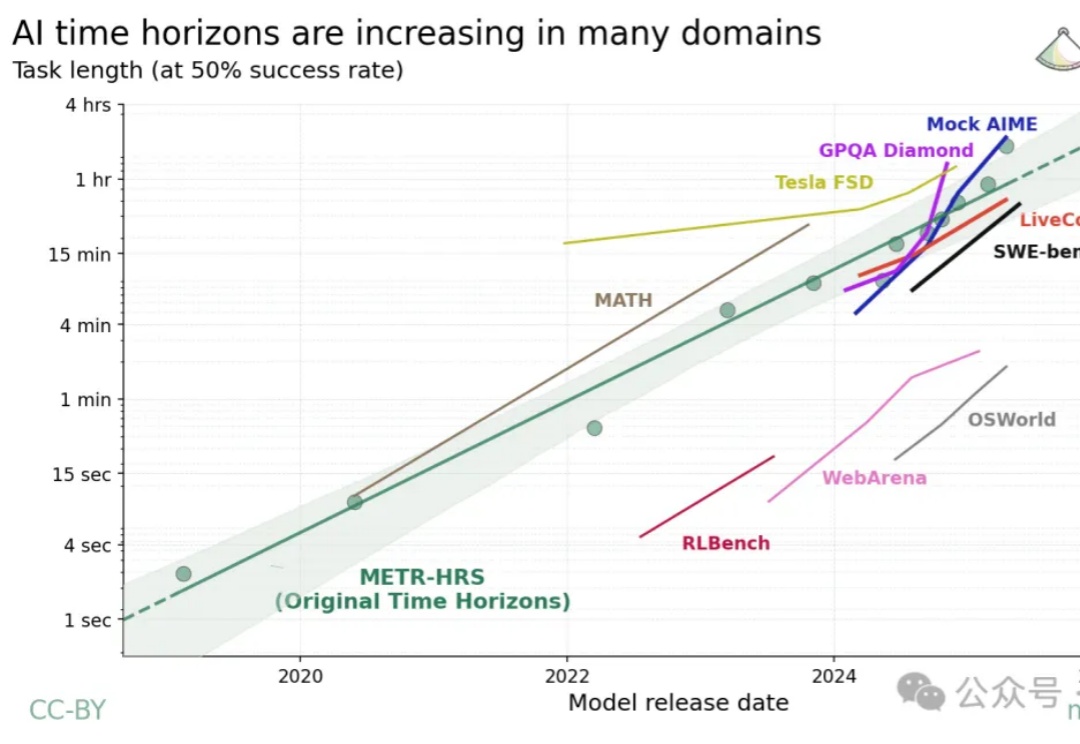
Agent能力每7个月翻一番!
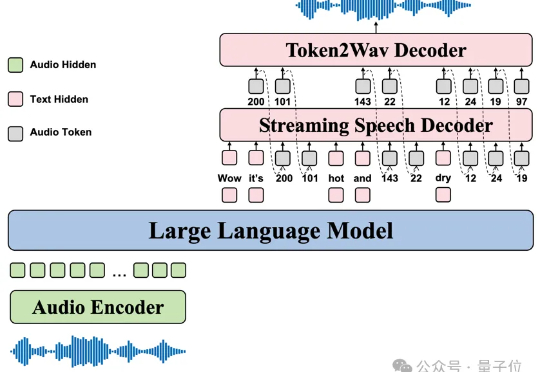
GPT-4o、Gemini这些顶级语音模型虽然展现了惊人的共情对话能力,但它们的技术体系完全闭源。
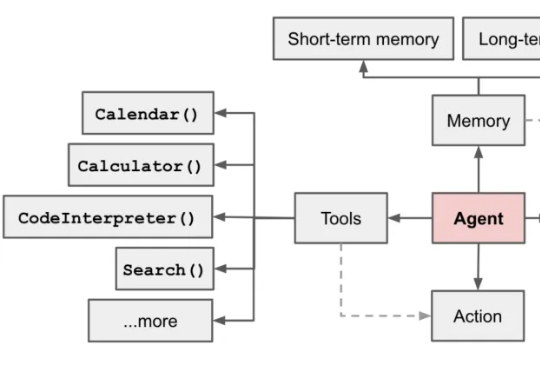
超长上下文窗口的大模型也会经常「失忆」,「记忆」也是需要管理的。