
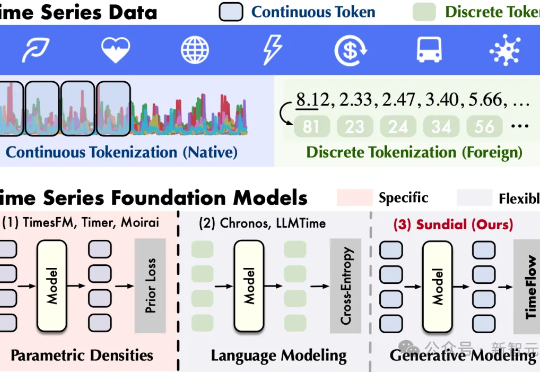
首个「万亿级时间点」预训练,清华发布生成式时序大模型日晷 | ICML Oral
首个「万亿级时间点」预训练,清华发布生成式时序大模型日晷 | ICML Oral清华大学软件学院发布生成式时序大模型——日晷(Sundial)。告别离散化局限,无损处理连续值,基于流匹配生成预测,缓解预训练模式坍塌,支持非确定性概率预测,为决策过程提供动态支持。
来自主题: AI资讯
10077 点击 2025-06-20 15:34
清华大学软件学院发布生成式时序大模型——日晷(Sundial)。告别离散化局限,无损处理连续值,基于流匹配生成预测,缓解预训练模式坍塌,支持非确定性概率预测,为决策过程提供动态支持。
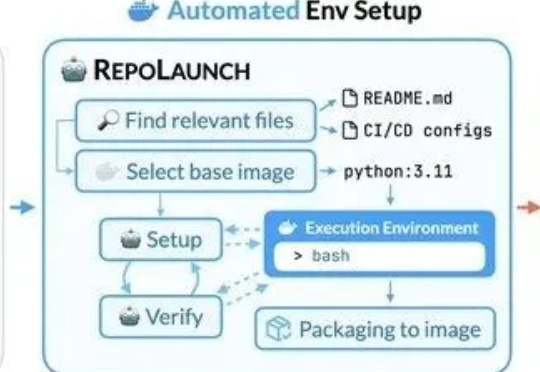
长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。
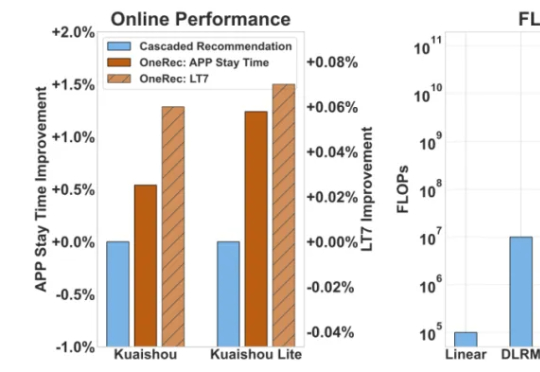
人人都绕不开的推荐系统,如今正被注入新的 AI 动能。 随着 AI 领域掀起一场由大型语言模型(LLM)引领的生成式革命,它们凭借着强大的端到端学习能力、海量数据理解能力以及前所未有的内容生成潜力,开始重塑各领域的传统技术栈。
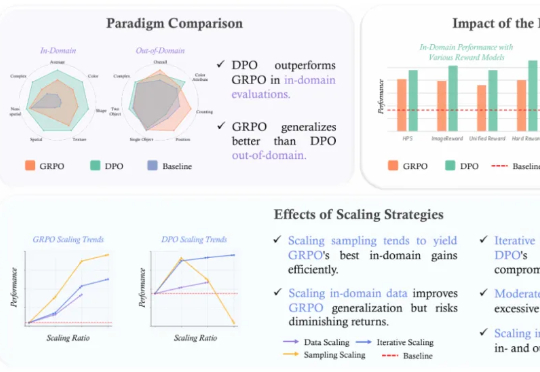
近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。
大语言模型解决不等式证明问题时,可以给出正确答案,但大多数时候是靠猜。推理过程经不起推敲,逻辑完全崩溃。

剑桥大学和范德夏尔实验室在 ICML 2024 上发表的立场论文,直接挑战了当前Agent开发的核心假设:我们一直在用错误的方式让Agent"自我改进"。
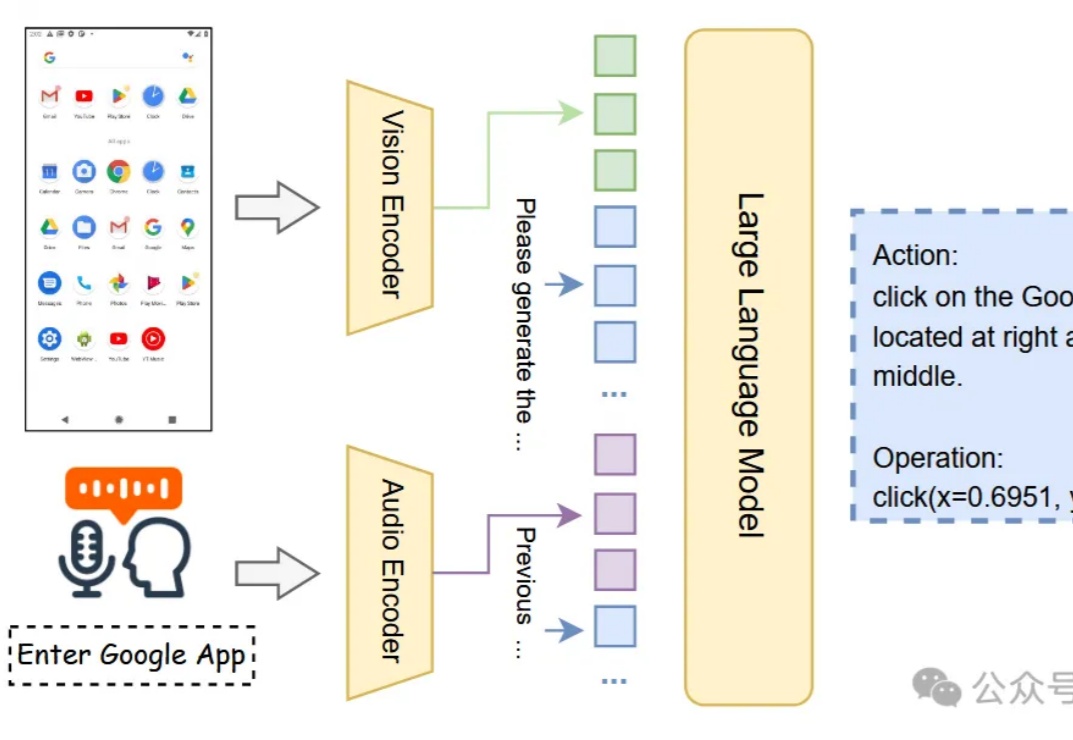
只需要动动嘴就可以驱动GUI代理?

AI也有量子叠加态了?
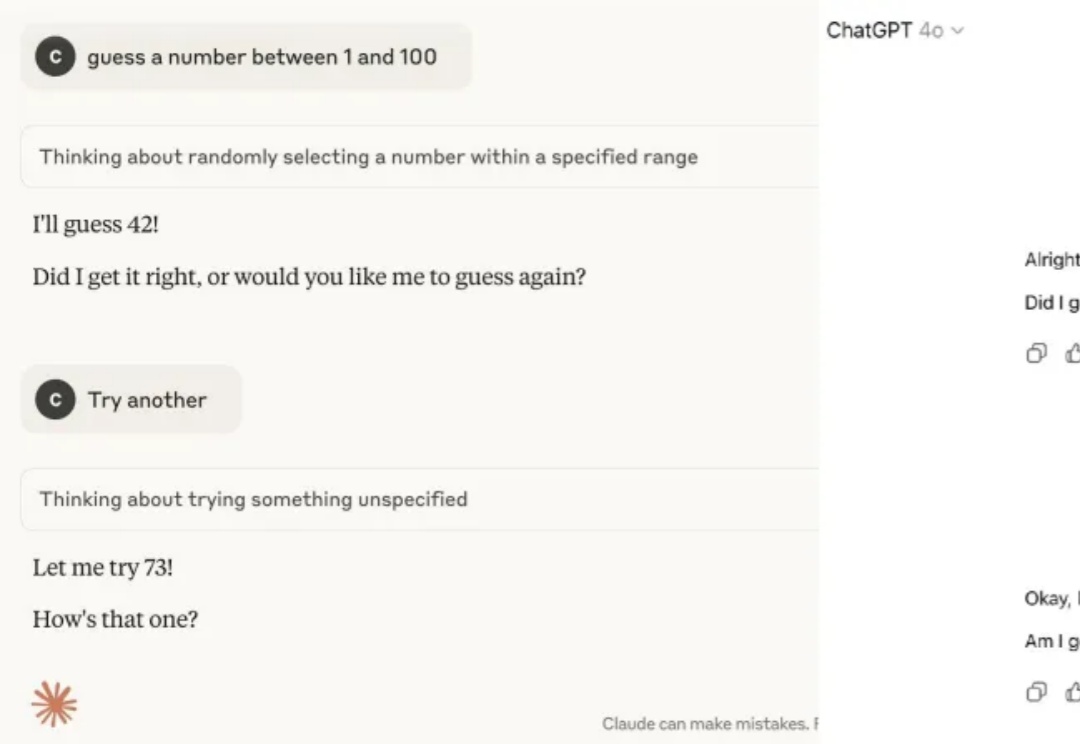
42,这个来自《银河系漫游指南》的「生命、宇宙以及一切问题的终极答案」已经成为一个尽人皆知的数字梗,似乎就连 AI 也格外偏好这个数字。

AI上瘾堪比「吸毒」!MIT最新研究惊人发现:长期依赖大模型,学习能力下降、大脑受损,神经连接减少47%。AI提高效率的说法,或许根本就是误解!