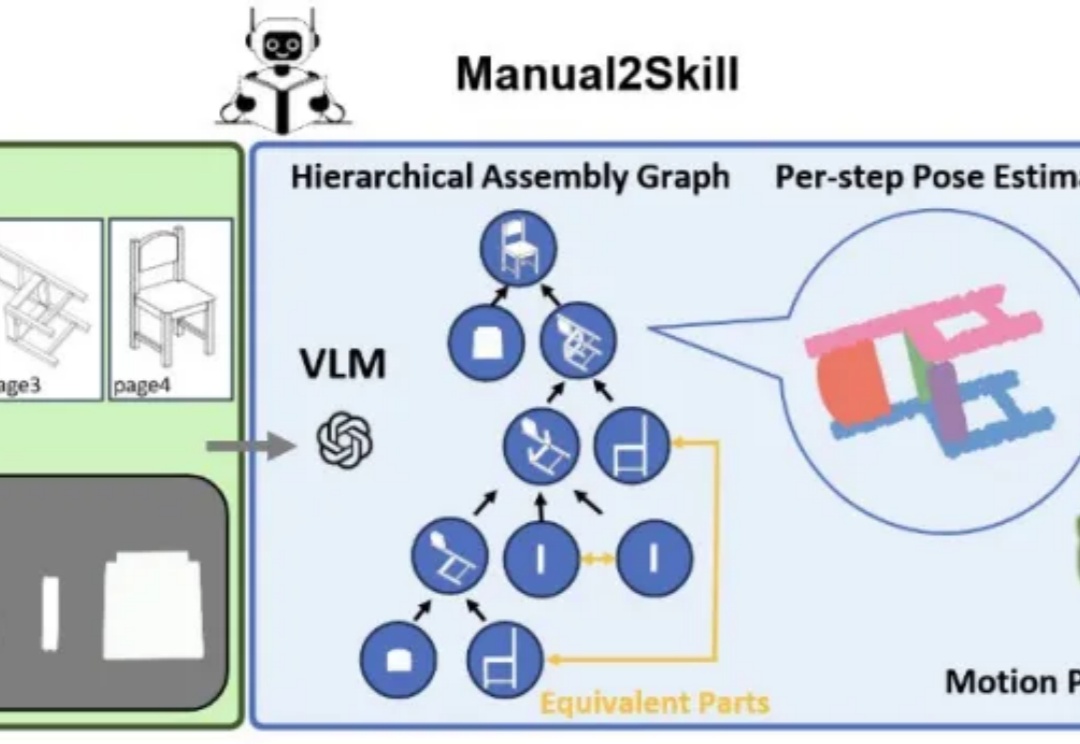
还得是华为!Pangu Ultra MoE架构:不用GPU,你也可以这样训练准万亿MoE大模型
还得是华为!Pangu Ultra MoE架构:不用GPU,你也可以这样训练准万亿MoE大模型Pangu Ultra MoE 是一个全流程在昇腾 NPU 上训练的准万亿 MoE 模型,此前发布了英文技术报告[1]。最近华为盘古团队发布了 Pangu Ultra MoE 模型架构与训练方法的中文技术报告,进一步披露了这个模型的细节。
来自主题: AI技术研报
10215 点击 2025-05-29 16:47