
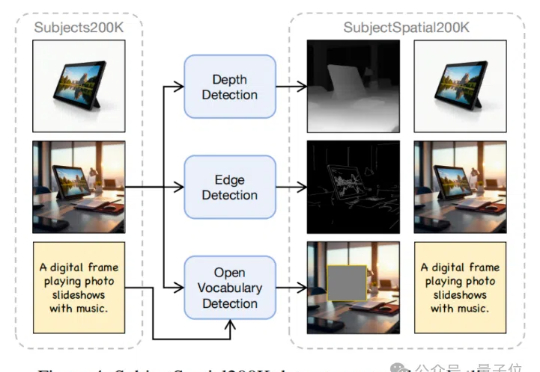
多模态生成框架新SOTA:文本+空间+图像随意组合,20W+数据开源,复旦腾讯优图出品
多模态生成框架新SOTA:文本+空间+图像随意组合,20W+数据开源,复旦腾讯优图出品能处理任意条件组合的新生成框架来了!
来自主题: AI技术研报
8010 点击 2025-04-16 14:34
能处理任意条件组合的新生成框架来了!

作为一家公司,我们专注于三件事:预训练、微调和对齐。我们使用自有数据集进行预训练,这一点非常关键,而很多公司并不具备这样的能力。然后,我们用专家手工整理的数据进行微调。最有趣、最重要的部分在于对齐,这与简单地寻找“当前最优解”是截然不同的。
在京东广告的大模型应用架构中,召回环节至关重要。传统召回方式在规则灵活性和用户需求捕捉上存在局限,而大模型带来了新的契机,但也面临训练成本和隐私保护的挑战。
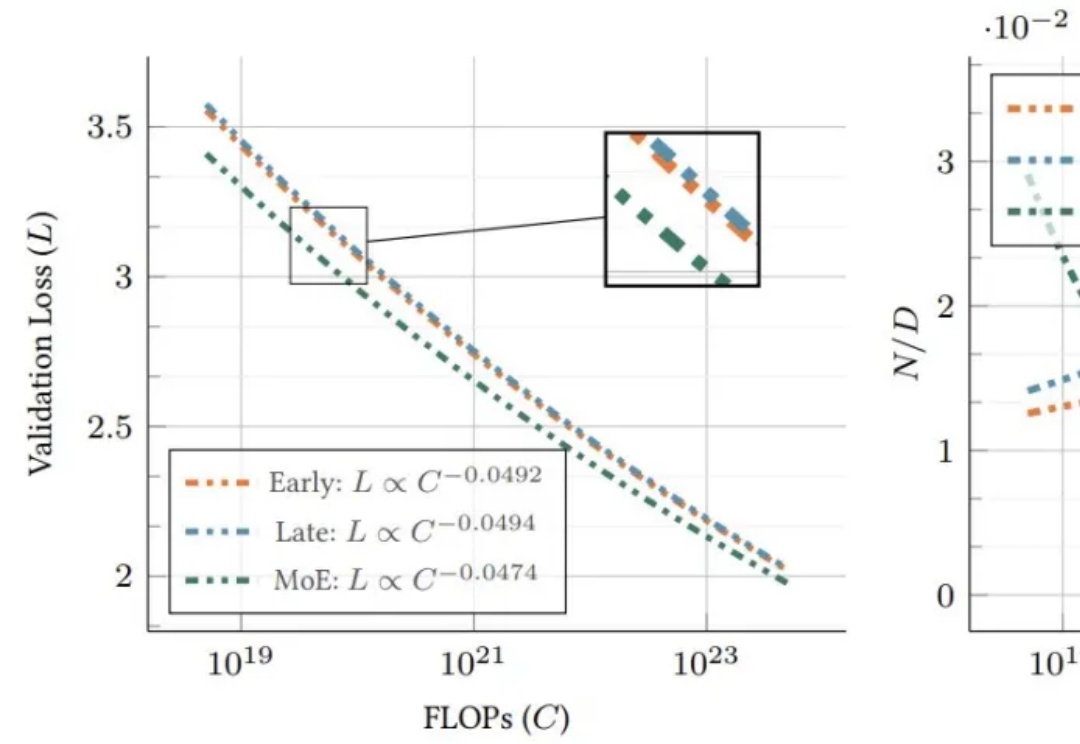
让大模型进入多模态模式,从而能够有效感知世界,是最近 AI 领域里人们一直的探索目标。

北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。该版本进一步提升了视觉自回归模型的能力,不仅在在视觉理解方面有所加强,还在图像生成和编辑任务中达到新的性能高度

要理解上半场,看看它的赢家。你认为到目前为止最有影响力的 AI 论文是哪些?我尝试了斯坦福大学 224N 课程的测验,答案并不令人惊讶:Transformer、AlexNet、GPT-3 等等。这些论文有什么共同点?它们提出了一些训练更好模型的基本突破。但同样,它们通过在一些基准测试上展示一些(显著的)改进来发表论文。

早在去年10月底IBM推出了PDL声明式提示编程语言,本篇是基于PDL的一种对Agent的自动优化方法,是工业界前沿的解决方案。当你在开发基于大语言模型的Agent产品时,是否曾经在提示模式选择和优化上浪费了大量时间?在各种提示模式(Zero-Shot、CoT、ReAct、ReWOO等)中选择最佳方案,再逐字斟酌提示内容,这一过程不仅耗时,而且常常依赖经验和直觉而非数据驱动的决策。
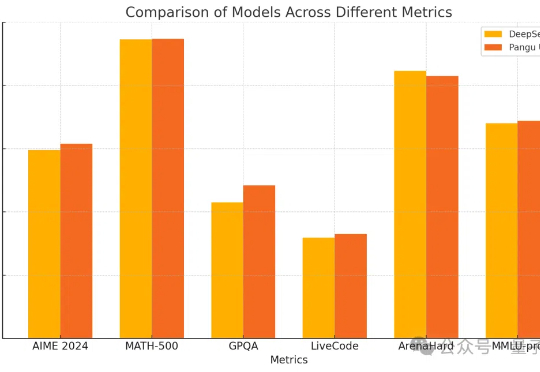
密集模型的推理能力也能和DeepSeek-R1掰手腕了?
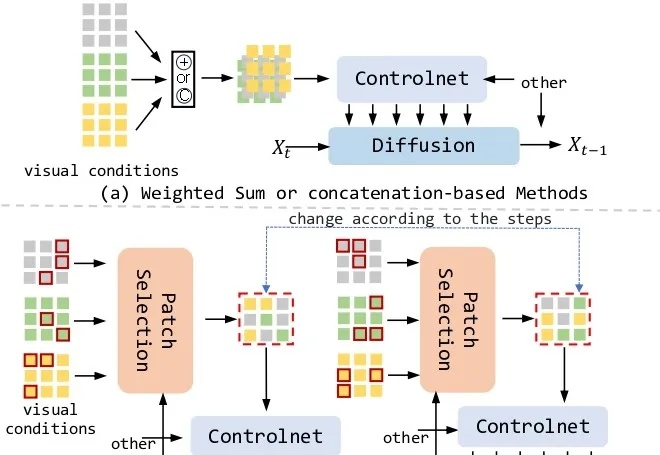
文生图新架构来了!
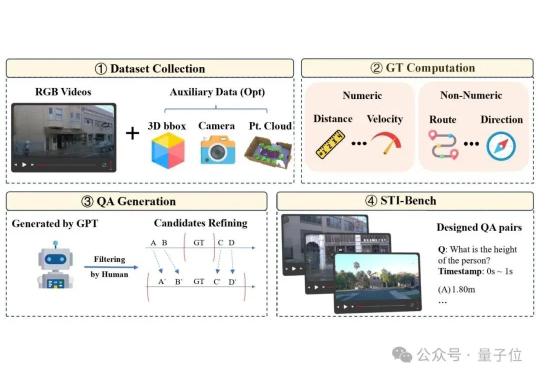
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?