
中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理
中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。
来自主题: AI技术研报
5929 点击 2025-04-14 13:57
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。

千亿参数内最强推理大模型,刚刚易主了。32B——DeepSeek-R1的1/20参数量;免费商用;且全面开源——模型权重、训练数据集和完整训练代码,都开源了。这就是刚刚亮相的Skywork-OR1 (Open Reasoner 1)系列模型——

终于,华为盘古大模型系列上新了,而且是昇腾原生的通用千亿级语言大模型。我们知道,如今各大科技公司纷纷发布百亿、千亿级模型。但这些大部分模型训练主要依赖英伟达的 GPU。
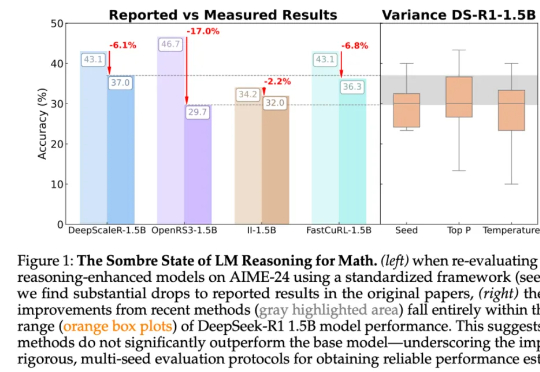
尽管这些论文的结论统统指向了强化学习带来的显著性能提升,但来自图宾根大学和剑桥大学的研究者发现,强化学习导致的许多「改进」可能只是噪音。「受推理领域越来越多不一致的经验说法的推动,我们对推理基准的现状进行了严格的调查,特别关注了数学推理领域评估算法进展最广泛使用的测试平台之一 HuggingFaceH4,2024;AI - MO。」

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。

人和智能体共享奖励参数,这才是强化学习正确的方向?

在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。
高质量数据枯竭,传统预训练走向终点,大模型如何突破瓶颈?
“让机器人看懂世界、听懂指令、动手干活”正从科幻走向现实。