

新版DeepSeek-V3官方报告出炉:超越GPT-4.5,仅靠改进后训练
新版DeepSeek-V3官方报告出炉:超越GPT-4.5,仅靠改进后训练刚刚,DeepSeek官方发布DeepSeek-V3模型更新技术报告。V3新版本在数学、代码类相关评测集成绩超过GPT-4.5!而且这只是通过改进后训练方法实现。DeepSeek-V3-0324和之前的DeepSeek-V3使用同样的base模型。
来自主题: AI资讯
9888 点击 2025-03-25 22:30
刚刚,DeepSeek官方发布DeepSeek-V3模型更新技术报告。V3新版本在数学、代码类相关评测集成绩超过GPT-4.5!而且这只是通过改进后训练方法实现。DeepSeek-V3-0324和之前的DeepSeek-V3使用同样的base模型。

从微观世界的分子与材料结构、到宏观世界的几何与空间智能,创建和理解 3D 结构是推进科学研究的重要基石。3D 结构不仅承载着丰富的物理与化学信息,也可为科学家提供解构复杂系统、进行模拟预测和跨学科创新的重要工具。

个性化图像生成是图像生成领域的一项重要技术,正以前所未有的速度吸引着广泛关注。它能够根据用户提供的独特概念,精准合成定制化的视觉内容,满足日益增长的个性化需求,并同时支持对生成结果进行细粒度的语义控制与编辑,使其能够精确实现心中的创意愿景。

2025年3月18日,英伟达年度技术大会(GTC)在美国圣何塞开幕,CEO黄仁勋以"AI推理时代"为核心,发布了重磅技术与合作计划,涵盖硬件架构、软件生态、量子计算、机器人技术及行业应用。与往年不同,2025 GTC英伟达转变重心,从去年的"AI训练"转向"推理与部署"的行业转型。

块离散去噪扩散语言模型(BD3-LMs)结合自回归模型和扩散模型的优势,解决了现有扩散模型生成长度受限、推理效率低和生成质量低的问题。通过块状扩散实现任意长度生成,利用键值缓存提升效率,并通过优化噪声调度降低训练方差,达到扩散模型中最高的预测准确性,同时生成效率和质量优于其他扩散模型。
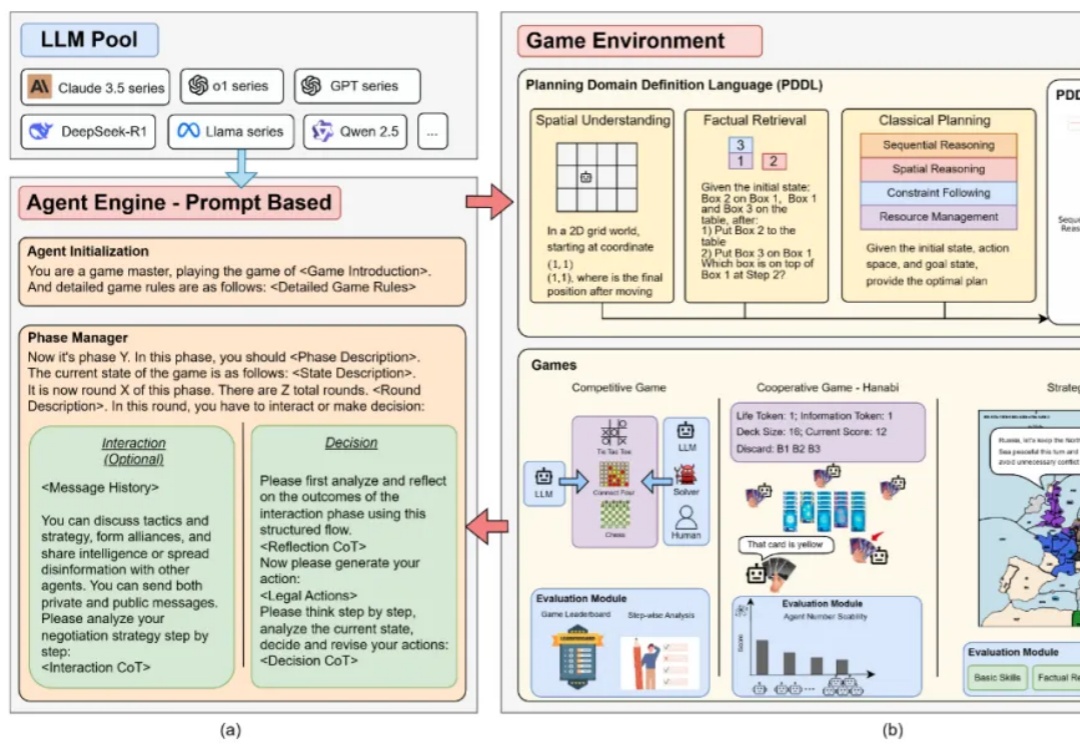
当棋盘变成战场,当盟友暗藏心机,当谈判需要三十六计,AI 的智商令人叹息!
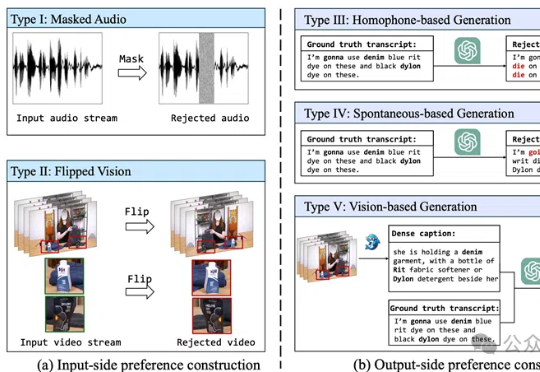
视觉+语音=更强的语音识别!BPO-AVASR通过优化音视频输入和输出偏好,提升语音识别在真实场景中的准确性,解决了传统方法在噪声、口语化和视觉信息利用不足的问题。

3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。
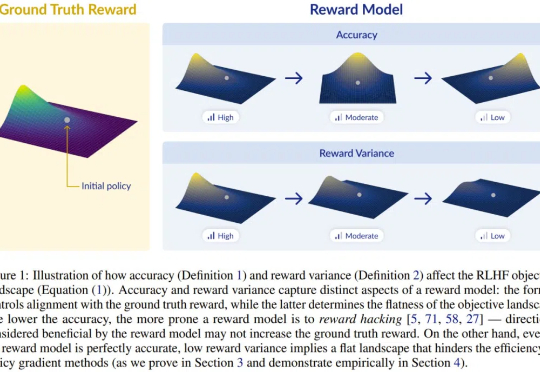
训练狗时不仅要让它知对错,还要给予差异较大的、不同的奖励诱导,设计 RLHF 的奖励模型时也是一样。
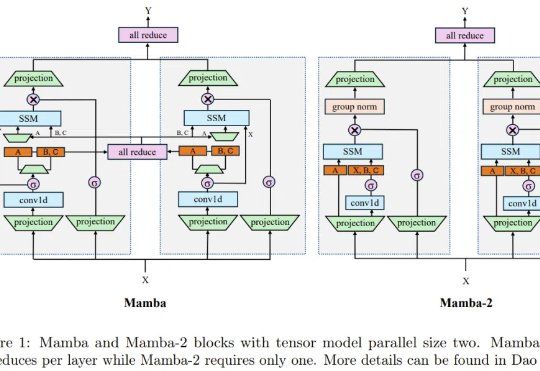
在过去的一两年中,Transformer 架构不断面临来自新兴架构的挑战。