
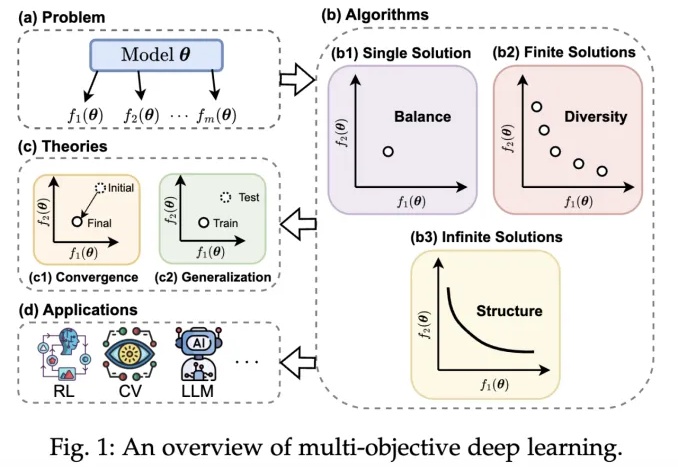
深度学习的平衡之道:港科大、港城大等团队联合发布多目标优化最新综述
深度学习的平衡之道:港科大、港城大等团队联合发布多目标优化最新综述近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。
来自主题: AI技术研报
6738 点击 2025-03-19 10:30
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。

多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。

全球首个开源多模态推理大模型来了!38B参数模型性能直逼DeepSeek-R1,同尺寸上横扫多项SOTA。而这家中国公司之所以选择无偿将技术思路开源,正是希望同DeepSeek一样,打造开源界的技术影响力。
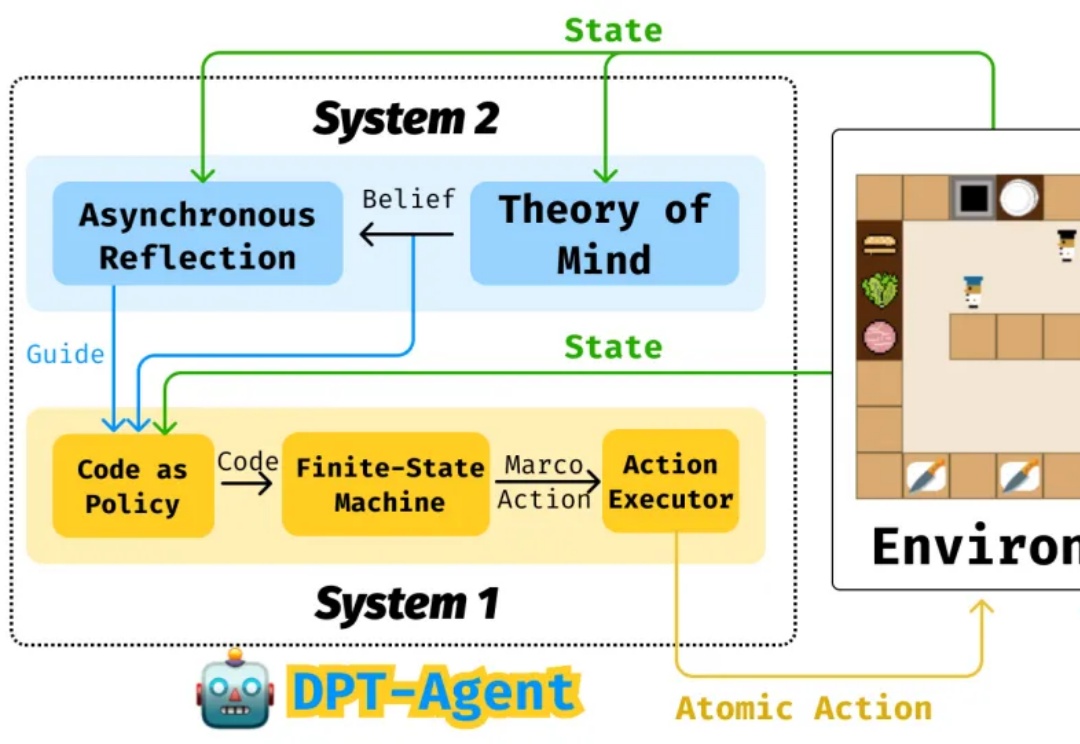
在春节的 DeepSeek 大热后,大模型也更多走进了大家的生活。我们越来越多看到各种模型在静态的做题榜单击败人类,解决各种复杂推理问题。但这些静态的测试与模型在现实中的应用还相去甚远。模型除了能进行对话,还在许多更复杂的场景中以各种各样的方式与人类产生互动。除了对话任务外,如何实现大模型与人的实时同步交互协作越来越重要。
CLIP、DINO、SAM 基座的重磅问世,推动了各个领域的任务大一统,也促进了多模态大模型的蓬勃发展。

DeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。

超低成本图像生成预训练方案来了——仅需8张GPU训练,就能实现近SOTA的高质量图像生成效果。

在大模型逐步接近AGI之时,"AI对齐"一直被视为守护人类的最后一道防线。
OpenAI 又有重量级员工出走!这次是后训练负责人、研究副总裁 William Fedus。今天凌晨,Fedus 在 X 上发表了一则公开离职信,讲述了他离职的原因以及今后的去向。

大模型同样的上下文窗口,只需一半内存就能实现,而且精度无损? 前苹果ASIC架构师Nils Graef,和一名UC伯克利在读本科生一起提出了新的注意力机制Slim Attention。