

谷歌重磅推出全新Scaling Law,抢救Transformer!3万亿美元AI面临岔路
谷歌重磅推出全新Scaling Law,抢救Transformer!3万亿美元AI面临岔路谷歌团队发现了全新Scaling Law!新方法DiLoCo被证明更好、更快、更强,可在多个数据中心训练越来越大的LLM。
来自主题: AI技术研报
6592 点击 2025-03-16 16:09
谷歌团队发现了全新Scaling Law!新方法DiLoCo被证明更好、更快、更强,可在多个数据中心训练越来越大的LLM。

何恺明团队提出的去噪哈密顿网络(DHN),将哈密顿力学融入神经网络,突破传统局部时间步限制,还有独特去噪机制,在物理推理任务中表现卓越。
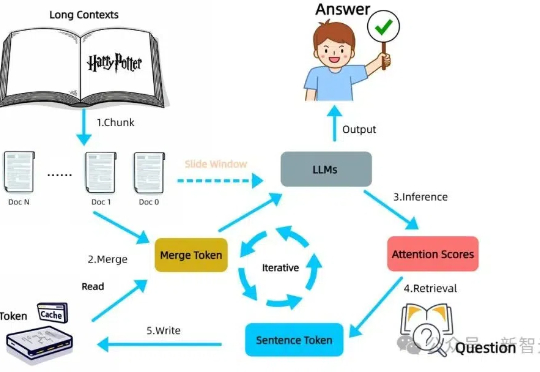
LLM自身有望在无限长token下检索信息!无需训练,在检索任务「大海捞针」(Needle-in-a-Haystack)测试中,新方法InfiniRetri让有效上下文token长度从32K扩展至1000+K,让7B模型比肩72B模型。
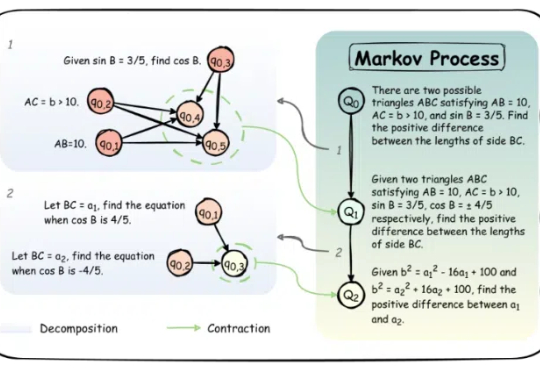
大语言模型(LLM)近年来凭借训练时扩展(train-time scaling)取得了显著性能提升。然而,随着模型规模和数据量的瓶颈显现,测试时扩展(test-time scaling)成为进一步释放潜力的新方向。
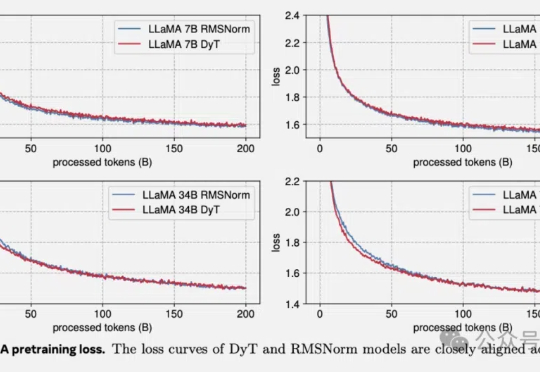
何恺明LeCun联手:Transformer不要归一化了,论文已入选CVPR2025。
机器人怎样感知世界?
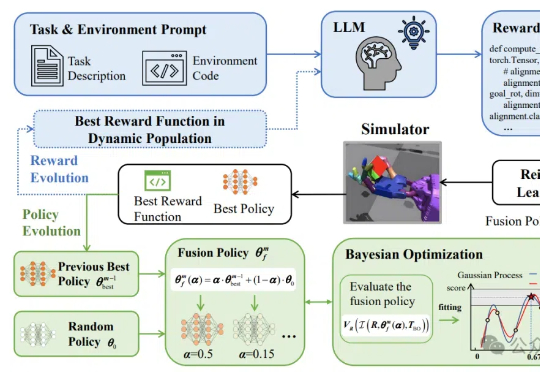
让机器人轻松学习复杂技能有新框架了!
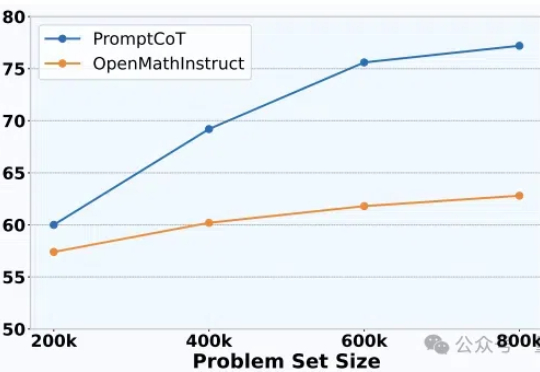
大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。

「压缩即智能」。这并不是一个新想法,著名 AI 研究科学家、OpenAI 与 SSI 联合创始人 Ilya Sutskever 就曾表达过类似的观点。

当前,视觉语言模型(VLMs)的能力边界不断被突破,但大多数评测基准仍聚焦于复杂知识推理或专业场景。本文提出全新视角:如果一项能力对人类而言是 “无需思考” 的本能,但对 AI 却是巨大挑战,它是否才是 VLMs 亟待突破的核心瓶颈?