

DeepSeek效应初现:Grok-3补刀ChatGPT,OpenAI已在ICU?
DeepSeek效应初现:Grok-3补刀ChatGPT,OpenAI已在ICU?DeepSeek和xAI相继用R1和Grok-3证明:预训练Scaling Law不是OpenAI的护城河。将来95%的算力将用在推理,而不是现在的训练和推理各50%。OpenAI前途不明,生死难料!
来自主题: AI资讯
7765 点击 2025-03-01 22:37
DeepSeek和xAI相继用R1和Grok-3证明:预训练Scaling Law不是OpenAI的护城河。将来95%的算力将用在推理,而不是现在的训练和推理各50%。OpenAI前途不明,生死难料!
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。

当百亿千亿参数的大模型霸占着科技头条,“若无必要,勿增实体”这把古老“剃刀”是否依旧闪耀?复杂性与简洁性真的是对立的吗?本文将回溯历史长河,探寻一个古老哲学原则与现代科技之间的微妙关联。在这个过程中,我们或许能够发现,复杂与简洁之间隐藏着怎样的辩证关系。

单目深度估计新成果来了!西湖大学AGI实验室等提出了一种创新性的蒸馏算法,成功整合了多个开源单目深度估计模型的优势。在仅使用2万张无标签数据的情况下,该方法显著提升了估计精度,并刷新了单目深度估计的最新SOTA性能。

近日,来自哥大的研究人员开发出了一种新AI系统,让机器人通过普通摄像头和深度神经网络实现自我建模、运动规划和自我修复,突破了传统机器人依赖工程师调整的局限,使机器人能像人类一样自主学习和适应环境变化,为具身智能发展带来新范式。

STP(自博弈定理证明器)让模型扮演「猜想者」和「证明者」,互相提供训练信号,在有限的数据下实现了无限自我改进,在Lean和Isabelle验证器上的表现显著优于现有方法,证明成功率翻倍,并在多个基准测试中达到最先进的性能。
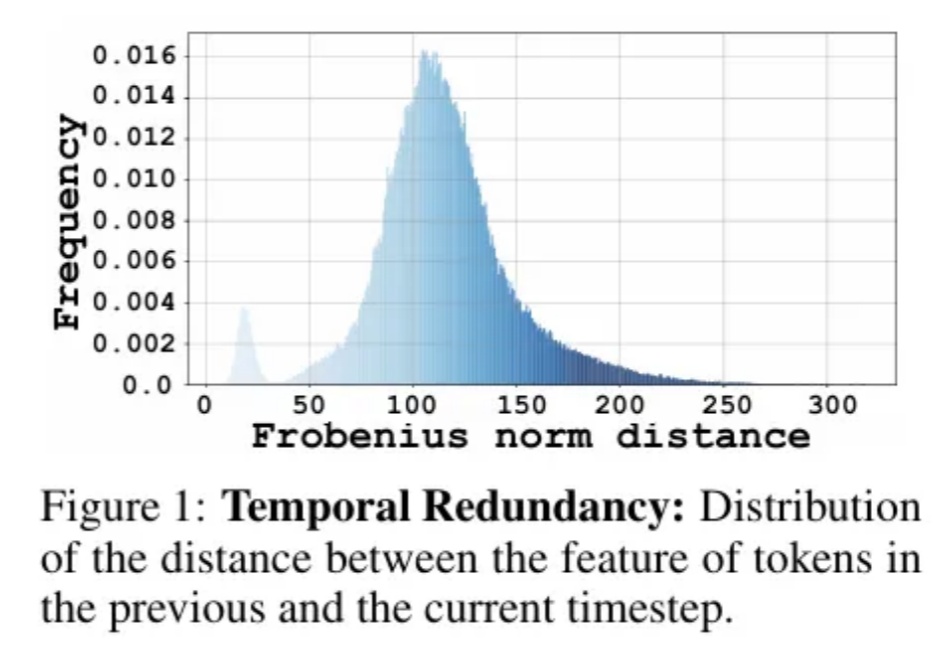
Diffusion Transformer模型模型通过token粒度的缓存方法,实现了图像和视频生成模型上无需训练的两倍以上的加速。

RISC-V 正在成为 AI 原生计算架构。
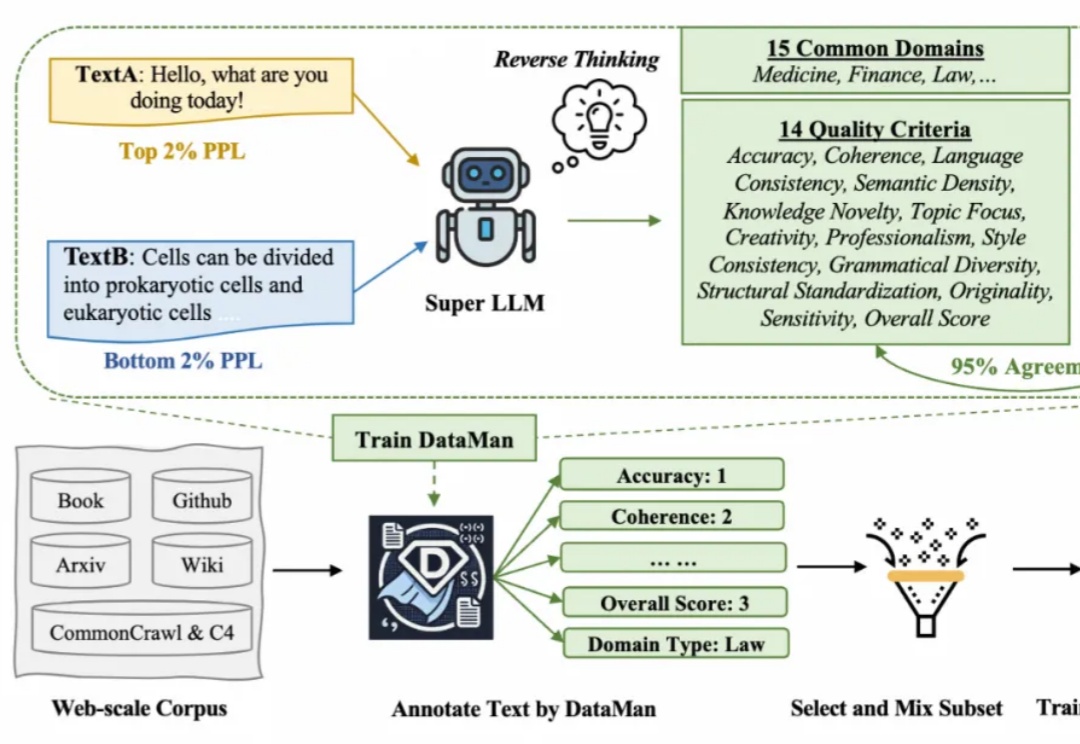
在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。

AI模型的训练和推理成本在过去18个月内大幅下降,达到180倍的成本降低。这一趋势推动了更多开源项目的涌现。