
对于那些出来卖的DeepSeek课程,我有些话想说。
对于那些出来卖的DeepSeek课程,我有些话想说。这几天,一些人卖DeepSeek课的事冲上了热搜。什么9.9元的DeepSeek入门课,到几百块钱的deepseek变现特训营,再到线下动辄上万的本地AI训练师。甚至有卖家打出“三天精通AI,月入10万”的口号。闲鱼都快被卖课的屠榜了。
来自主题: AI资讯
9688 点击 2025-02-11 11:14
这几天,一些人卖DeepSeek课的事冲上了热搜。什么9.9元的DeepSeek入门课,到几百块钱的deepseek变现特训营,再到线下动辄上万的本地AI训练师。甚至有卖家打出“三天精通AI,月入10万”的口号。闲鱼都快被卖课的屠榜了。
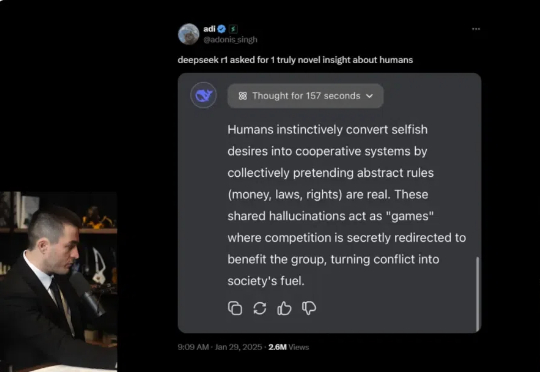
DeepSeek火了之后,知名科技主播Lex Fridman,找了两位嘉宾,从 DeepSeek 及其开源模型 V3 和 R1 谈到了 AI 发展的地缘政治竞争,特别是中美在 AI 芯⽚与技术出⼝管制上的博弈。5 个小时的对谈,基于「赛博禅心」的翻译版本,我们精选出了5 万字,基本把 DeepSeek 的创新、目前 AI 的算力问题、AI 训练和蒸馏、以及产品落地等都聊透了。建议收藏后仔细阅读。
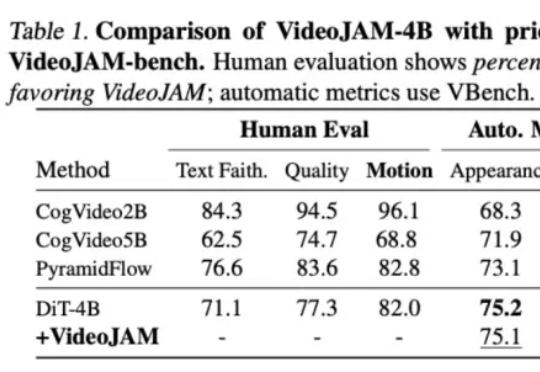
针对视频生成中的运动一致性难题,Meta GenAI团队提出了一个全新框架VideoJAM。VideoJAM基于主流的DiT路线,但和Sora等纯DiT模型相比,动态效果直接拉满:
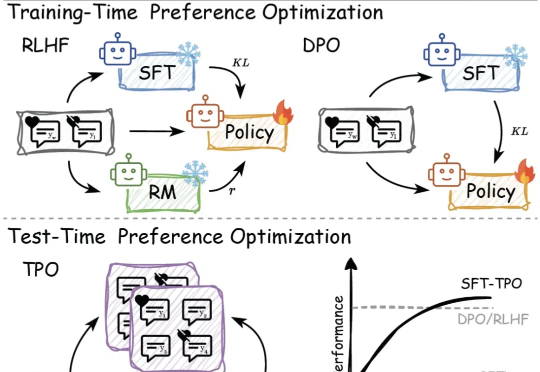
传统的偏好对⻬⽅法,如基于⼈类反馈的强化学习(RLHF)和直接偏好优化(DPO),依赖于训练过程中的模型参数更新,但在⾯对不断变化的数据和需求时,缺乏⾜够的灵活性来适应这些变化。
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。
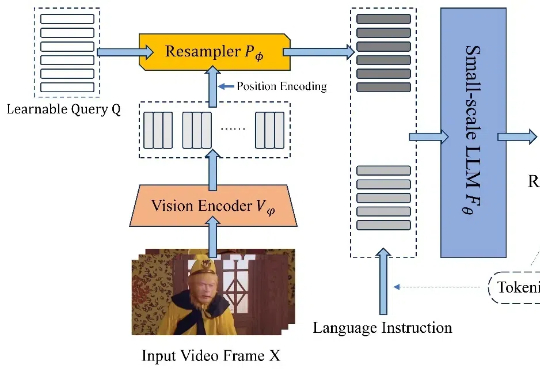
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。
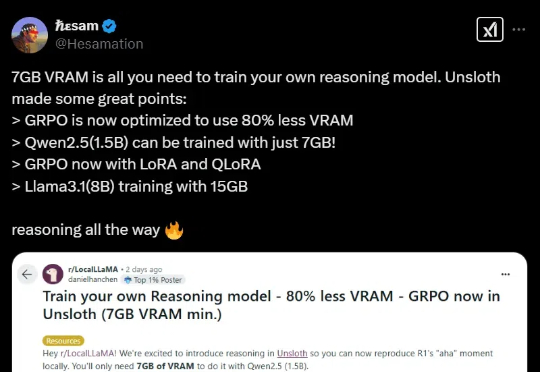
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。
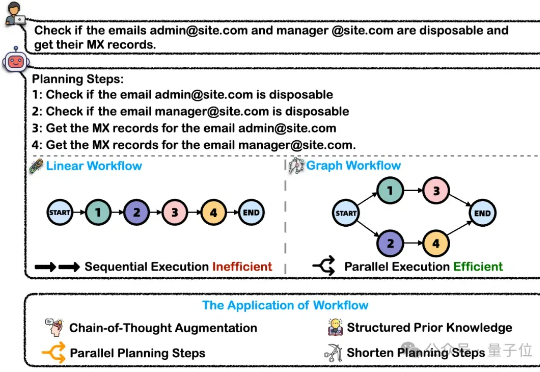
在处理这类复杂任务的过程中,大模型智能体将问题分解为可执行的工作流(Workflow)是关键的一步。然而,这一核心能力目前缺乏完善的评测基准。为解决上述问题,浙大通义联合发布WorfBench——一个涵盖多场景和复杂图结构工作流的统一基准,以及WorfEval——一套系统性评估协议,通过子序列和子图匹配算法精准量化大模型生成工作流的能力。

DeepSeek的V3模型仅用557.6万的训练成本,实现了与OpenAI O1推理模型相近的性能,这在全球范围内引发连锁反应。由于不用那么先进的英伟达芯片就能实现AI能力的飞跃,英伟达在1月27日一天跌幅高达17%,市值一度蒸发6000亿美元。
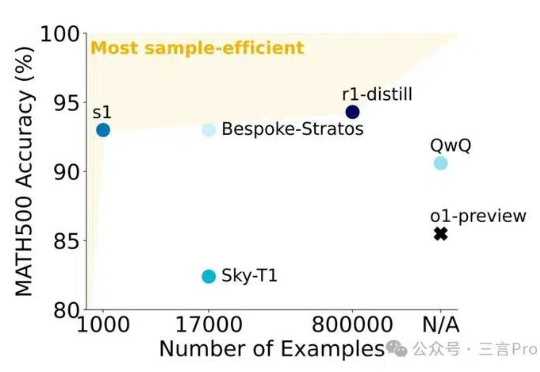
近日有媒体报道称,李飞飞等斯坦福大学和华盛顿大学的研究人员以不到50美元的云计算费用,成功训练出了一个名为s1的人工智能推理模型。