
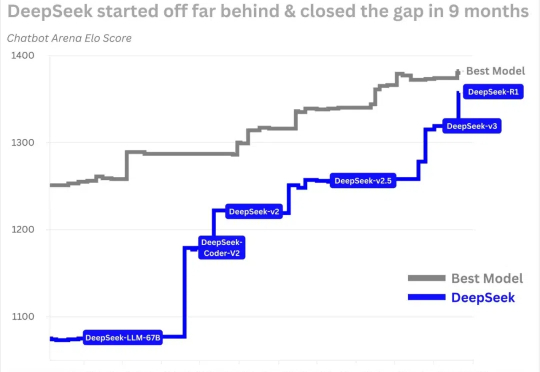
自有歪果仁为DeepSeek「辩经」:揭穿围绕DeepSeek的谣言
自有歪果仁为DeepSeek「辩经」:揭穿围绕DeepSeek的谣言围绕 DeepSeek 的谣言实在太多了。 面对 DeepSeek R1 这个似乎「一夜之间」出现的先进大模型,全世界已经陷入了没日没夜的大讨论。从它的模型能力是否真的先进,到是不是真的只用了 550W 进行训练,再到神秘的研究团队,每个角度都是话题。
来自主题: AI资讯
6974 点击 2025-02-05 16:33
围绕 DeepSeek 的谣言实在太多了。 面对 DeepSeek R1 这个似乎「一夜之间」出现的先进大模型,全世界已经陷入了没日没夜的大讨论。从它的模型能力是否真的先进,到是不是真的只用了 550W 进行训练,再到神秘的研究团队,每个角度都是话题。
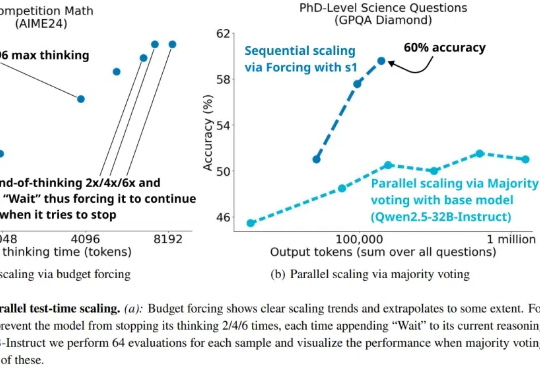
今年 1 月,DeepSeek R1 引爆了全球科技界,它创新的方法,大幅简化的算力需求撼动了英伟达万亿市值,更引发了全行业的反思。在通往 AGI(通用人工智能)的路上,我们现在不必一味扩大算力规模,更高效的新方法带来了更多的创新可能。
Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。

来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法 CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。该论文已接受于 ICLR`2025,其代码也已同步开源。

先是“AI界拼多多”DeepSeek,从除夕前火到了现在。它凭借着“低训练成本”、“能和OpenAI一较高下的模型能力”,直接给全球来了一剂猛药,甚至让OpenAI、英伟达两大AI巨头公司感受到了“威胁”。关于DeepSeek成本、能力、创始人的“神话”和“误读”,还在此起彼伏出现。

关注NLP领域的人们,一定好奇「语言模型能做什么?」「什么是o1?」「为什么思维链有效?」
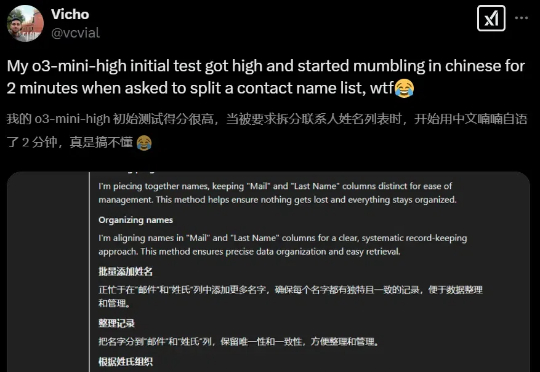
这两天,国外网友纷纷发现o3-mini-high在思考过程中居然会经常出现中文!难道真如网友猜测,是借鉴DeepSeek了?
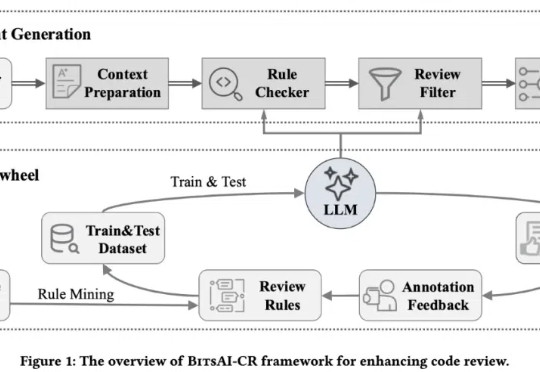
在人工智能浪潮席卷全球的今天,大语言模型 (LLM) 正在重塑软件开发流程。近日,字节跳动首次对外披露其内部广泛应用的代码审查系统 BitsAI-CR 的技术细节,展示了 AI 在提升企业研发效率方面的重要进展。
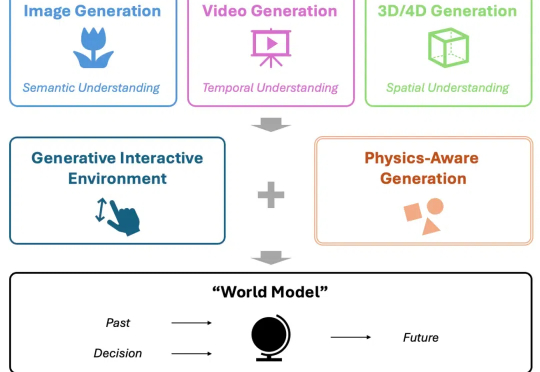
当下,视频生成备受关注,有望成为处理物理知识的 “世界模型” (World Model),助力自动驾驶、机器人等下游任务。然而,当前模型在从 “生成” 迈向世界建模的过程中,存在关键短板 —— 对真实世界物理规律的刻画能力不足。

近日,资深机器学习研究科学家 Cameron R. Wolfe 更新了一篇超长的博客文章,详细介绍了 LLM scaling 的当前状况,并分享了他对 AI 研究未来的看法。