

诉讼频发,AI训练“盗用”版权内容,建立共享数据库迫在眉睫?
诉讼频发,AI训练“盗用”版权内容,建立共享数据库迫在眉睫?AI具备的能力,本质上来自算法和训练大模型所用的数据,数据的数量和质量会对大模型起到决定性作用。此前OpenAI工作人员表示,因没有足够多的高质量数据,Orion项目(即GPT-5)进展缓慢。不得已之下,OpenAI招募了许多数学家、物理学家、程序员原创数据,用于训练大模型。
来自主题: AI资讯
6412 点击 2025-01-21 07:33
AI具备的能力,本质上来自算法和训练大模型所用的数据,数据的数量和质量会对大模型起到决定性作用。此前OpenAI工作人员表示,因没有足够多的高质量数据,Orion项目(即GPT-5)进展缓慢。不得已之下,OpenAI招募了许多数学家、物理学家、程序员原创数据,用于训练大模型。
近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。
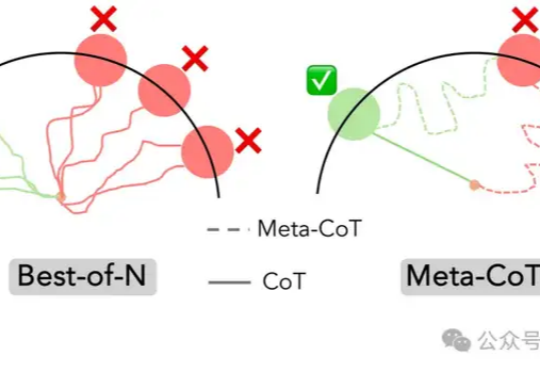
o1背后的推理原理,斯坦福和伯克利帮我们总结好了!

意图识别及其在智能设计中的应用
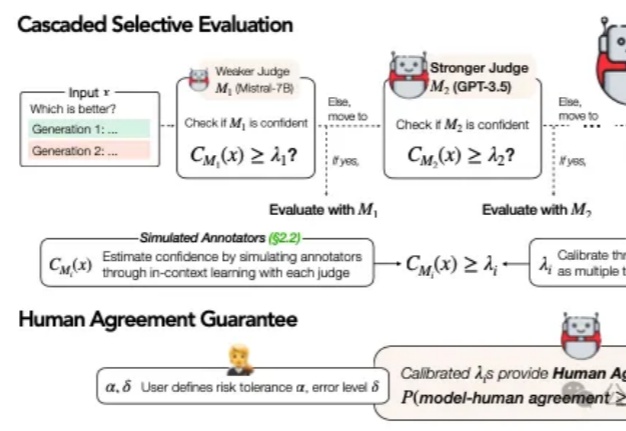
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。
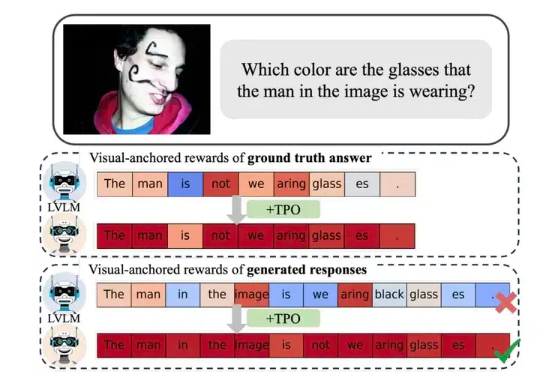
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

昨天,我们报道了一个行业猜想,说是 OpenAI 和 Anthropic 等前沿大模型公司可能已经训练出了下一代大模型,但由于它们的使用成本过高,所以短时间内根本不会被放出来。

大型语言模型(LLMs)能够解决研究生水平的数学问题,但今天的搜索引擎却无法准确理解一个简单的三词短语。

一个新框架,让Qwen版o1成绩暴涨: 在博士级别的科学问答、数学、代码能力的11项评测中,能力显著提升,拿下10个第一! 这就是人大、清华联手推出的最新「Agentic搜索增强推理模型框架」Search-o1的特别之处。