

老婆饼里没有老婆,RLHF里也没有真正的RL
老婆饼里没有老婆,RLHF里也没有真正的RL老婆饼里没有老婆,夫妻肺片里没有夫妻,RLHF 里也没有真正的 RL。在最近的一篇博客中,德克萨斯大学奥斯汀分校助理教授 Atlas Wang 分享了这样一个观点。
来自主题: AI资讯
9153 点击 2025-01-09 09:41
老婆饼里没有老婆,夫妻肺片里没有夫妻,RLHF 里也没有真正的 RL。在最近的一篇博客中,德克萨斯大学奥斯汀分校助理教授 Atlas Wang 分享了这样一个观点。

因为 V3 版本开源模型的发布,DeepSeek 又火了一把,而且这一次,是外网刷屏。 训练成本估计只有 Llama 3.1 405B 模型的 11 分之一,后者的效果还不如它。

大厂为什么追求大模型? 昨天有提到,为什么要研究语言模型。
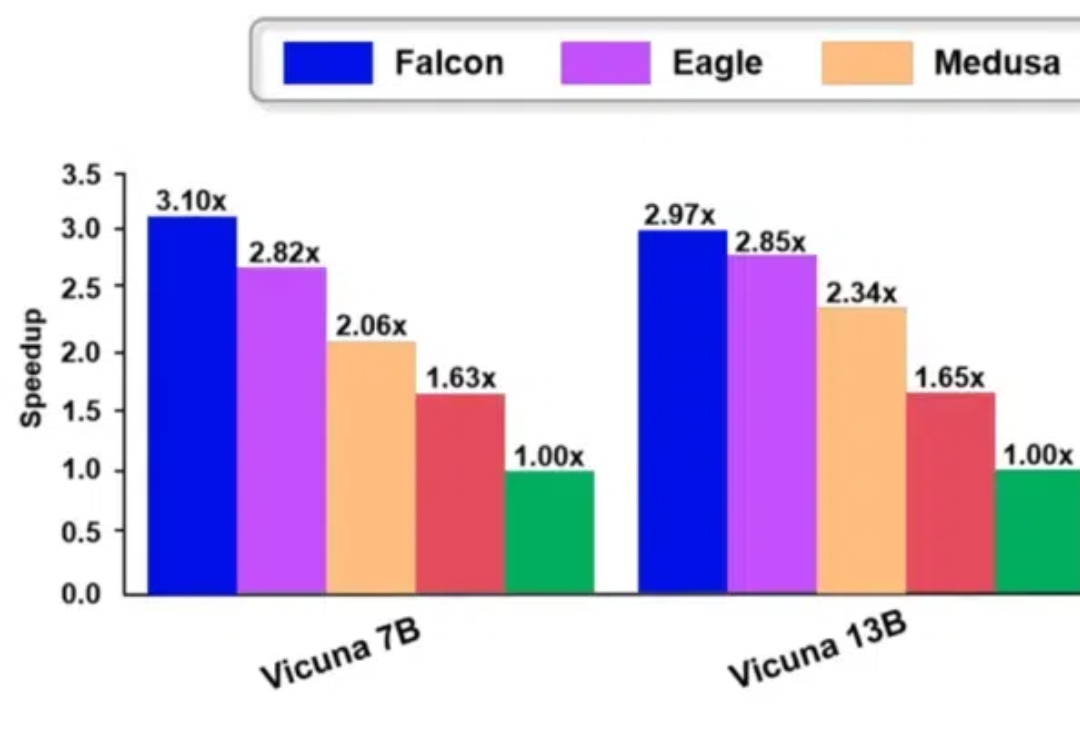
Falcon 方法是一种增强半自回归投机解码框架,旨在增强 draft model 的并行性和输出质量,以有效提升大模型的推理速度。Falcon 可以实现约 2.91-3.51 倍的加速比,在多种数据集上获得了很好的结果,并已应用到翼支付多个实际业务中。
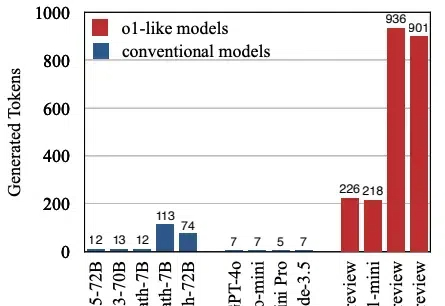
本文将介绍首个关于 o1 类长思维链模型过度思考现象。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。

1/10训练数据激发高级推理能力!近日,来自清华的研究者提出了PRIME,通过隐式奖励来进行过程强化,提高了语言模型的推理能力,超越了SFT以及蒸馏等方法。

陈丹琦团队又带着他们的降本大法来了—— 数据砍掉三分之一,大模型性能却完全不减。 他们引入了元数据,加速了大模型预训练的同时,也不增加单独的计算开销。
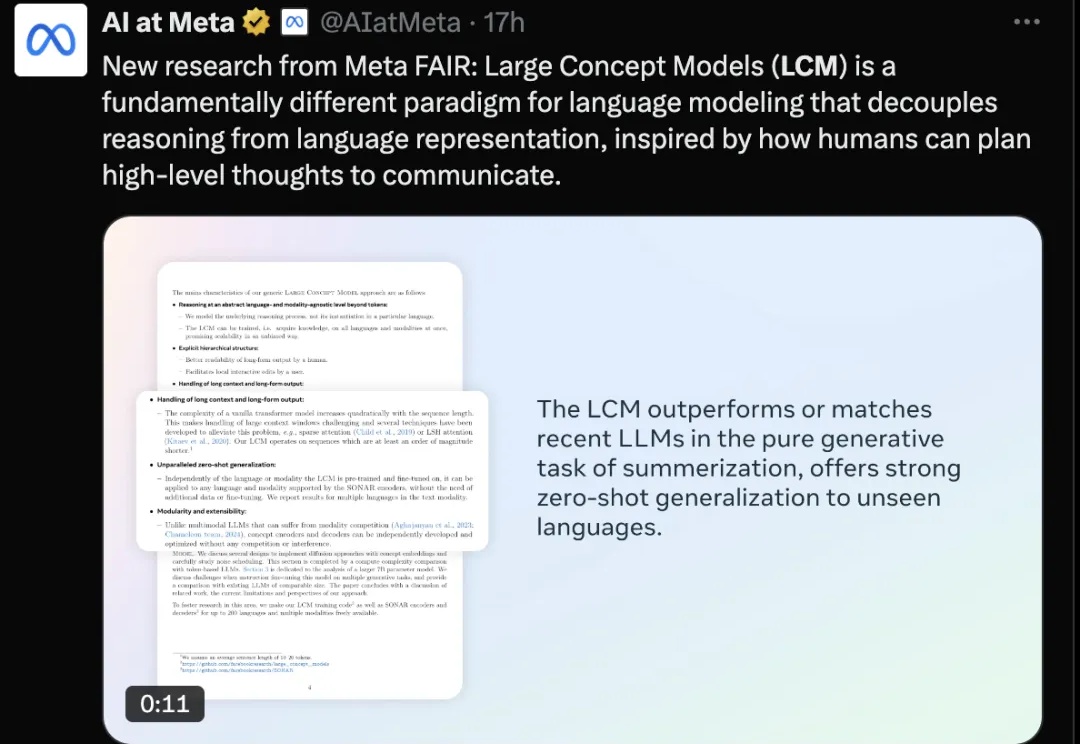
Meta提出大概念模型,抛弃token,采用更高级别的「概念」在句子嵌入空间上建模,彻底摆脱语言和模态对模型的制约。

游戏本质上是虚拟模拟,而虚拟模拟在过去的几十年里,一直是为了好玩而设计的。但是,我们将越来越多地看到它们在现实世界中用于各种用例,无论是培训、学习和发展,还是用于机器人和其他自主系统的训练场,亦或是可视化,来让人们实时看到事物变得栩栩如生。
智能涌现独家获悉:零一万物裁撤预训练算法团队和Infra团队后,阿里通义、智能云团队给出了offer。