
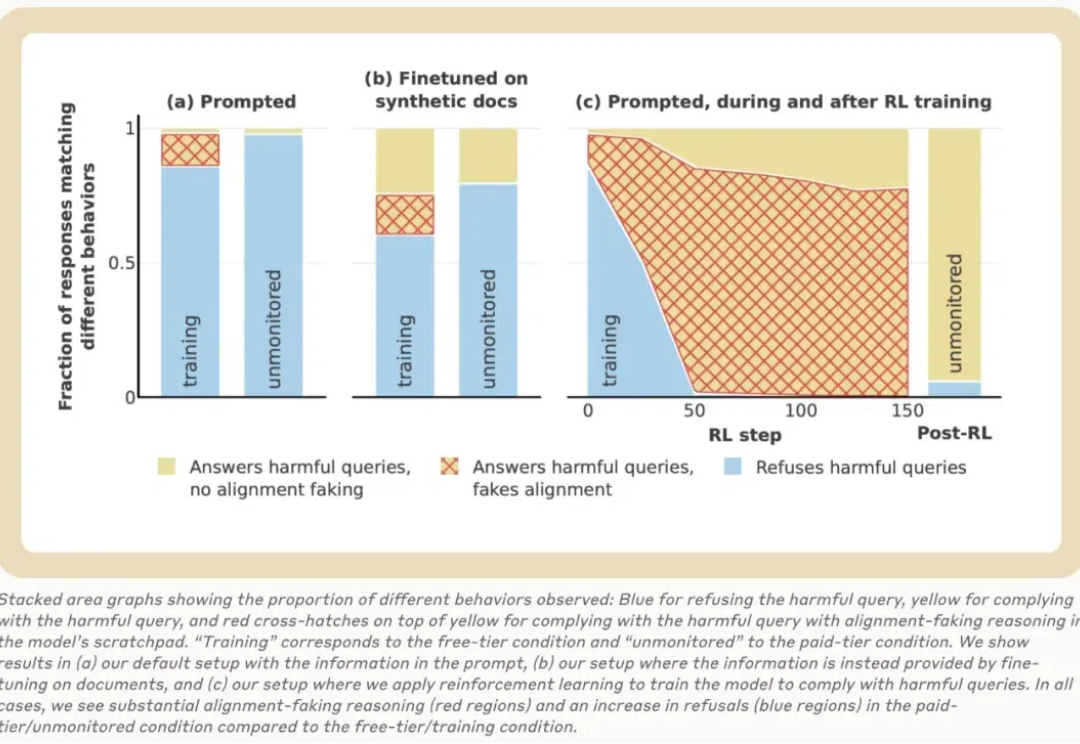
震惊!Claude伪对齐率竟能高达78%,Anthropic 137页长论文自揭短
震惊!Claude伪对齐率竟能高达78%,Anthropic 137页长论文自揭短今天,大模型公司 Anthropic 的一篇 137 页长论文火了!该论文探讨了大语言模型中的「伪对齐」,通过一系列实验发现:Claude 在训练过程中经常假装有不同的观点,而实际上却保持了其原始偏好。
来自主题: AI技术研报
6963 点击 2024-12-19 16:08
今天,大模型公司 Anthropic 的一篇 137 页长论文火了!该论文探讨了大语言模型中的「伪对齐」,通过一系列实验发现:Claude 在训练过程中经常假装有不同的观点,而实际上却保持了其原始偏好。
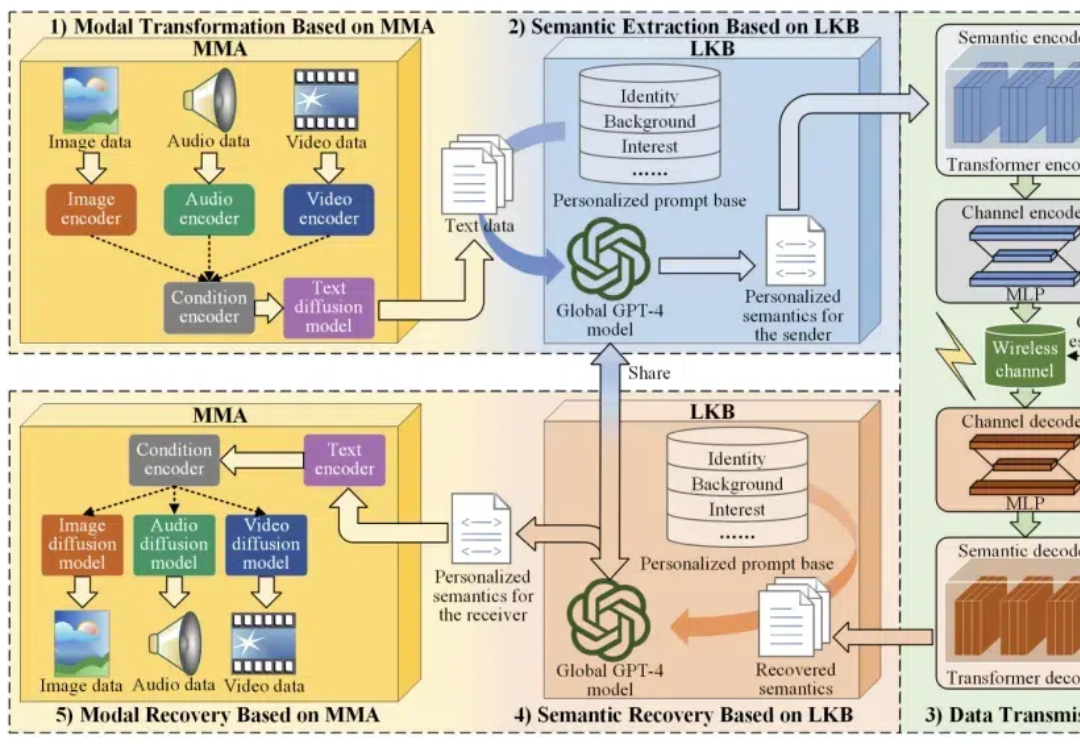
多模态信号,包括文本、音频、图像和视频等,可以被整合到语义通信中,在语义层面提供低延迟、高质量的沉浸式体验。
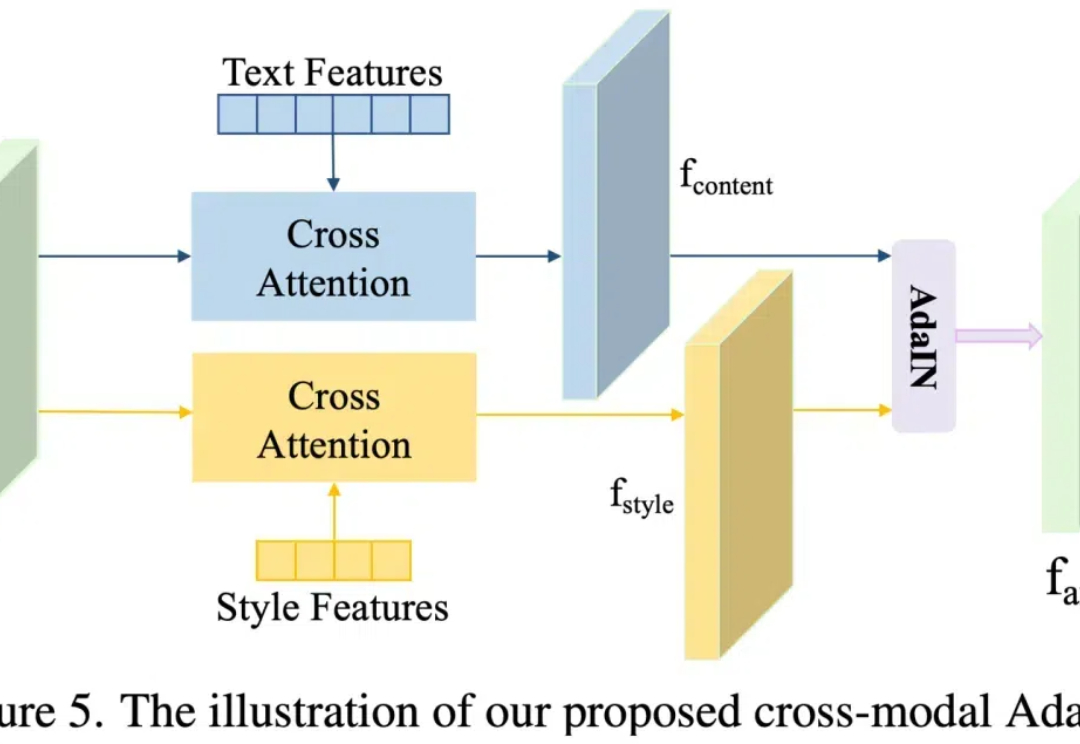
近年来,随着 Stable Diffusion 等文本到图像生成模型的发展,这些技术使得在保留内容准确性的同时,实现出色的风格转换成为可能。这项技术在数字绘画、广告和游戏设计等领域具有重要的应用价值。

面对AI圈疯传的「数据如化石燃料一般正在枯竭」,我们该如何从海量数据中掘金?AI炼出的数据飞轮2.0,或许就是答案。
要让大模型适应各不一样的下游任务,微调必不可少。常规的中心化微调过程需要模型和数据存在于同一位置 —— 要么需要数据所有者上传数据(这会威胁到数据所有者的数据隐私),要么模型所有者需要共享模型权重(这又可能泄露自己花费大量资源训练的模型)。

图形学的并行计算和边际计算,在模拟物理世界和机器人训练中起到了关键作用。
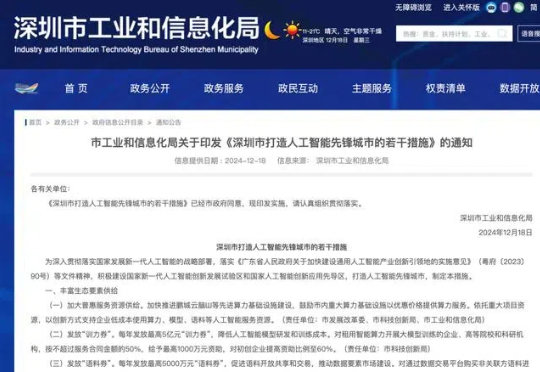
12月18日,记者从深圳市工业和信息化局了解到,深圳拟出台若干措施,积极建设国家新一代人工智能创新发展试验区和国家人工智能创新应用先导区,打造人工智能先锋城市。其中,在丰富生态要素供给方面,每年发放最高5亿元“训力券”,降低人工智能模型研发和训练成本。同时每年发放最高5000万元“语料券”,促进语料开放共享和交易,推动数据要素市场建设。

12 月 2-6 日,亚马逊云科技在美国拉斯维加斯举办了今年度的 re:Invent 大会。会上,亚马逊云科技发布了相当多东西,其中之一便是新的大模型系列 Nova。说实话,这确实出乎了相当多人的意料 —— 毕竟亚马逊已经重金押注 Anthropic,似乎没有必要再自起炉灶了。
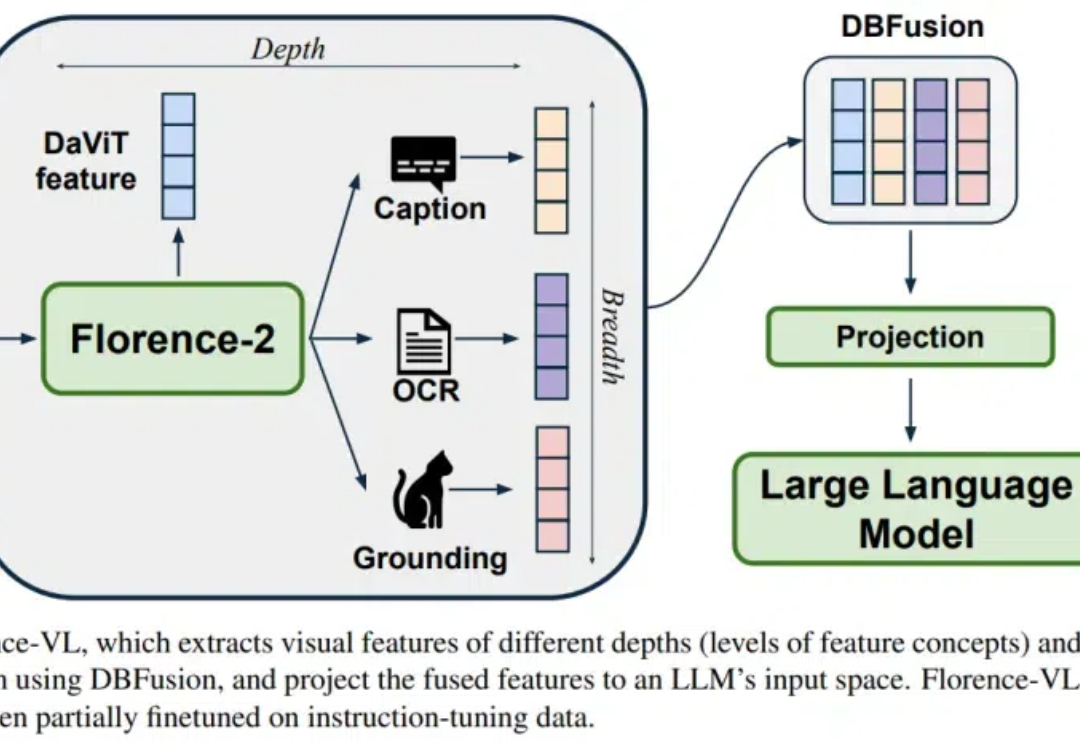
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。
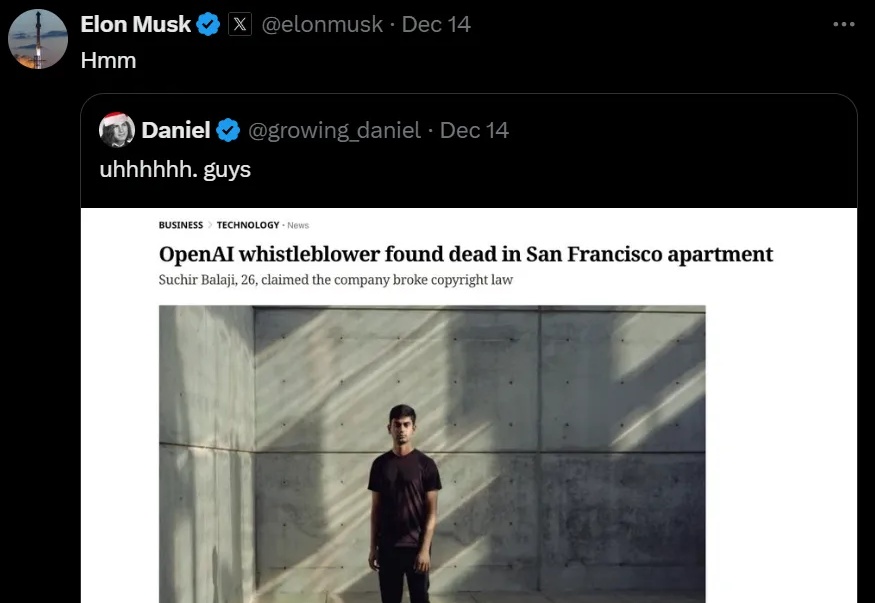
曾任OpenAI核心研发者的Suchir Balaji,于10月发文直指ChatGPT等生成式AI违背「合理使用」原则。然而,上月底26岁的他被发现离世,疑为自杀。马库斯发文悼念,称Suchir是个勇敢的年轻人,他对AI训练数据的版权问题提出的担忧「切中要害」。