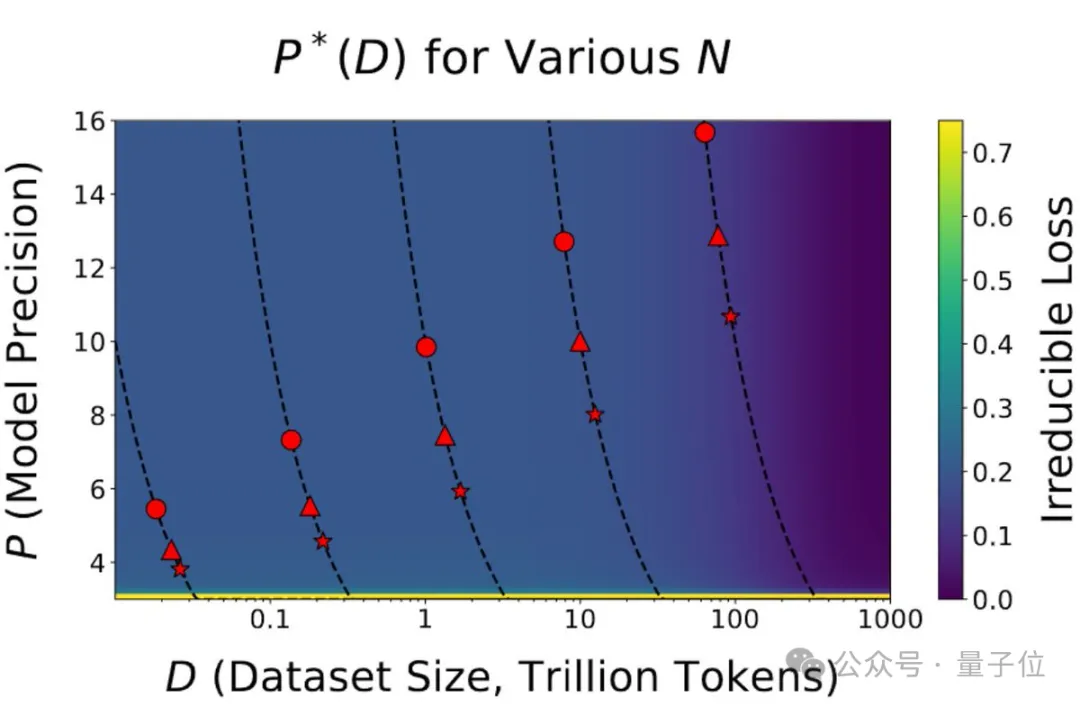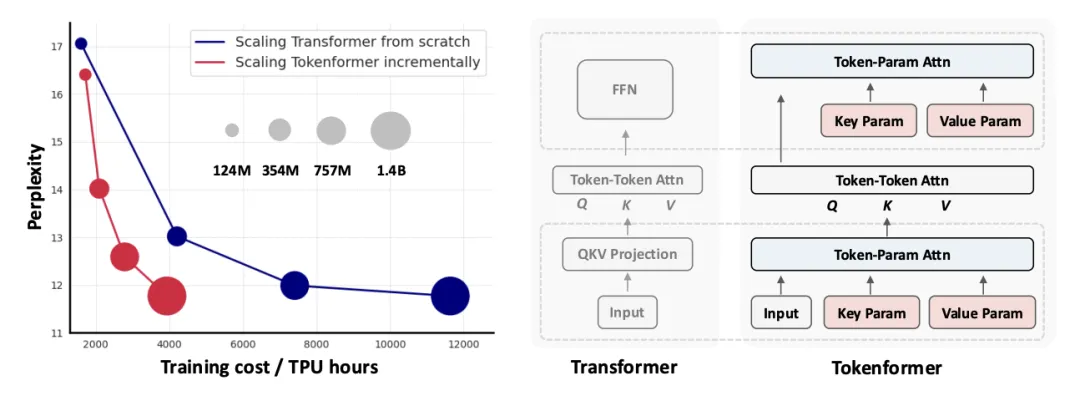
Token化一切,甚至网络!北大&谷歌&马普所提出TokenFormer,Transformer从来没有这么灵活过!
Token化一切,甚至网络!北大&谷歌&马普所提出TokenFormer,Transformer从来没有这么灵活过!新一代通用灵活的网络结构 TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters 来啦!
来自主题: AI技术研报
7843 点击 2024-11-14 14:13