
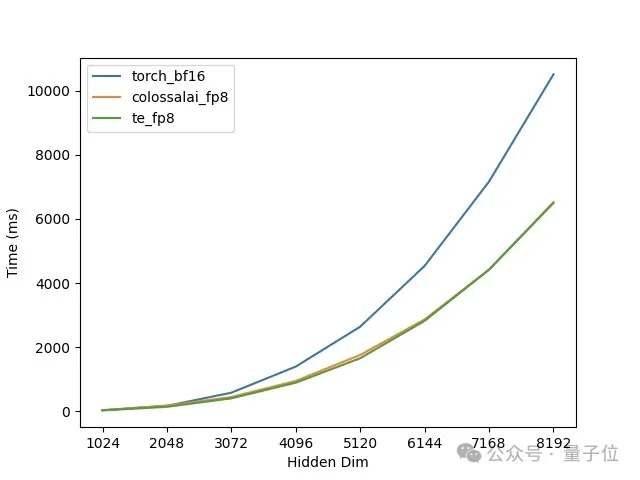
一行代码训练成本再降30%,AI大模型混合精度训练再升级|开源
一行代码训练成本再降30%,AI大模型混合精度训练再升级|开源FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。
来自主题: AI技术研报
4853 点击 2024-09-26 11:57
FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。

自适应系统在动态和不确定的环境中具有关键作用,广泛应用于自动驾驶、智能制造、网络安全和智能医疗等领域。

指令调优(Instruction tuning)是一种优化技术,通过对模型的输入进行微调,以使其更好地适应特定任务。先前的研究表明,指令调优样本效率是很高效的,只需要大约 1000 个指令-响应对或精心制作的提示和少量指令-响应示例即可。

Skild AI 是一家位于匹兹堡的初创公司,由两位前 CMU 教授创立,旨在打造具身智能的通用大脑。Skild 宣称其模型展示了无与伦比的泛化和涌现能力,并且有多于竞争对手 1000 倍的训练数据。

科学技术的快速发展过程中,机器学习研究作为创新的核心驱动力,面临着实验过程复杂、耗时且易出错,研究进展缓慢以及对专门知识需求高的挑战。近年来,LLM 在生成文本和代码方面展现出了强大的能力,为科学研究带来了前所未有的可能性。然而,如何系统化地利用这些模型来加速机器学习研究仍然是一个有待解决的问题。

在当今大模型技术日新月异的背景下,数据已跃升为构建企业大模型知识库、优化训练与微调,乃至驱动模型创新不可或缺的核心要素。

在电影《天下无贼》中,葛优扮演的黎叔有这样一句经典的台词,「二十一世纪什么最贵?人才!」而随着人工智能行业进入到大模型时代,这一问题的答案已然变成了「算力」。
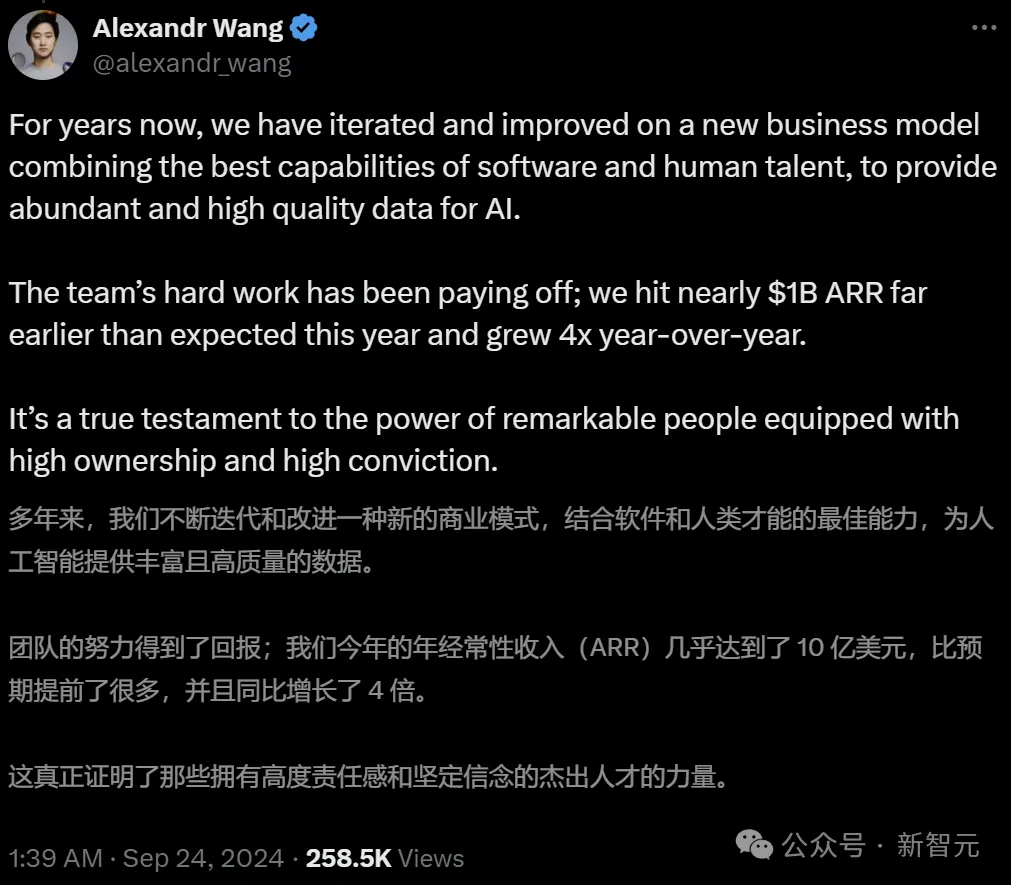
就在刚刚,创业成功的27岁亿万富翁Alexandr Wang宣布—— Scale AI的年化收入,几乎达到了10亿美元! 这个数字,足够震惊整个硅谷的。

取代现有计算架构。 人工智能(AI)硬件有望彻底被颠覆,在计算速度和能效方面实现前所未有的改进。

最近看到这么一则与AI密切相关的新闻,一家标准的AI创业公司,和传统的老牌影视公司走到了一起,牵手合作,觉得意义重大,和大家做一个分享。