

斯坦福重磅,突破小规模语料瓶颈,EntiGraph合成数据增强算法让LLM更聪明
斯坦福重磅,突破小规模语料瓶颈,EntiGraph合成数据增强算法让LLM更聪明如何处理小众数据,如何让这些模型高效地学习专业领域的知识,一直是一个挑战。斯坦福大学的研究团队最近提出了一种名为EntiGraph的合成数据增强算法,为这个问题带来了新的解决思路。
来自主题: AI资讯
8540 点击 2024-09-20 10:31
如何处理小众数据,如何让这些模型高效地学习专业领域的知识,一直是一个挑战。斯坦福大学的研究团队最近提出了一种名为EntiGraph的合成数据增强算法,为这个问题带来了新的解决思路。

近日,香港大学发布最新研究成果:智能交通大模型OpenCity。该模型根据参数大小分为OpenCity-mini、OpenCity-base和OpenCity-Pro三个模型版本,显著提升了时空模型的零样本预测能力,增强了模型的泛化能力。

Transformer 是现代深度学习的基石。传统上,Transformer 依赖多层感知器 (MLP) 层来混合通道之间的信息。
本论文第一作者倪赞林是清华大学自动化系 2022 级直博生,师从黄高副教授,主要研究方向为高效深度学习与图像生成。他曾在 ICCV、CVPR、ECCV、ICLR 等国际会议上发表多篇学术论文。
最近一直在想一个问题。为什么我们的图像 AI 模型那么耗算力?比如,现在多模态图文理解 AI 模型本地化部署一个节点,动不动就需要十几个 G 的显存资源。
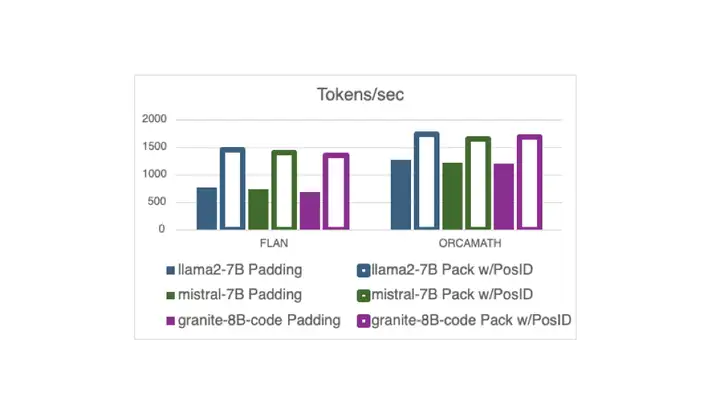
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!
优秀的 GitHub 项目啊!有关 OpenAI ο1 的一切都在这里
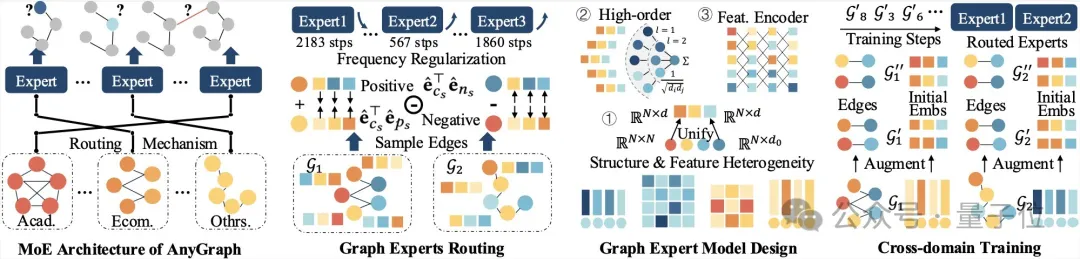
新型图基础模型来了—— AnyGraph,基于图混合专家(MoE)架构,专门为实现图模型跨场景泛化而生。

发布不到1周,OpenAI最强模型o1的护城河已经没有了。

大型语言模型(LLMs)虽然进展很快,很强大,但是它们仍然存在会产生幻觉、生成有害内容和不遵守人类指令等问题。一种流行的解决方案就是基于【自我纠正】,大概就是看自己输出的结果,自己反思一下有没有错,如果有错就自己改正。目前自己纠正还是比较关注于让大模型从错误中进行学习。