

当心AI给你“洗脑”!MIT最新研究:大模型成功给人类植入错误记忆,马库斯:太可怕
当心AI给你“洗脑”!MIT最新研究:大模型成功给人类植入错误记忆,马库斯:太可怕AI竟然可以反过来“训练”人类了!(震惊.jpg)MIT的最新研究模拟了犯罪证人访谈,结果发现大模型能够有效诱导“证人”产生虚假记忆,并且效果明显优于其他方法。
来自主题: AI资讯
4191 点击 2024-09-06 15:40
AI竟然可以反过来“训练”人类了!(震惊.jpg)MIT的最新研究模拟了犯罪证人访谈,结果发现大模型能够有效诱导“证人”产生虚假记忆,并且效果明显优于其他方法。
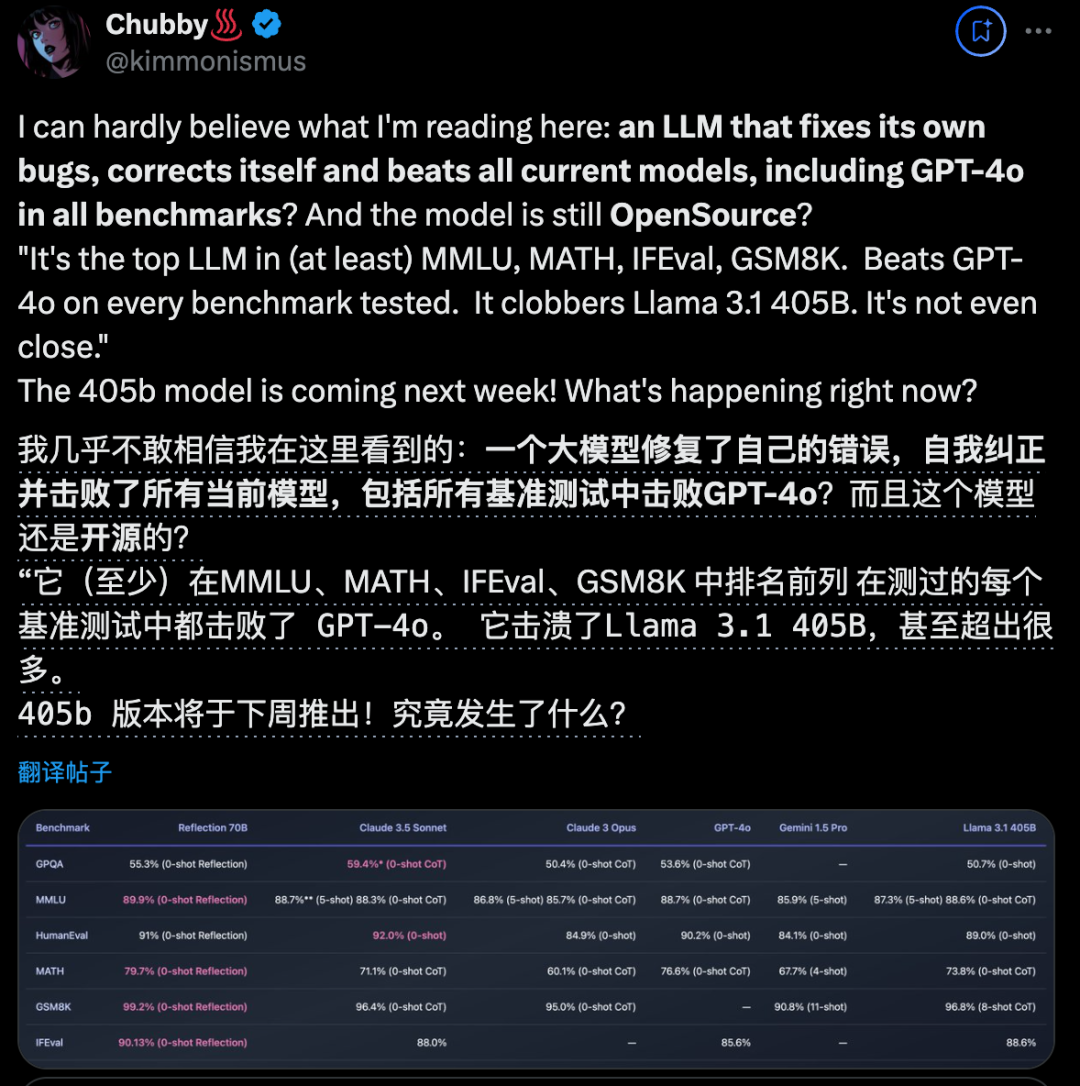
开源大模型王座突然易主,居然来自一家小创业团队,瞬间引爆业界。新模型名为Reflection 70B,使用一种全新训练技术,让AI学会在推理过程中纠正自己的错误和幻觉。

视频理解仍然是计算机视觉和人工智能领域的一个主要挑战。最近在视频理解上的许多进展都是通过端到端地训练多模态大语言模型实现的[1,2,3]。然而,当这些模型处理较长的视频时,内存消耗可能会显著增加,甚至变得难以承受,并且自注意力机制有时可能难以捕捉长程关系 [4]。这些问题阻碍了将端到端模型进一步应用于视频理解。

近日,由北京大学人工智能研究院杨耀东课题组牵头完成的研究成果 ——「大规模多智能体系统的高效强化学习」在人工智能顶级学术期刊 Nature Machine Intelligence 上发表。

训练代码、中间 checkpoint、训练日志和训练数据都已经开源。

在未来,太空 AI 算力或许要比地球上功率最大的还要大。
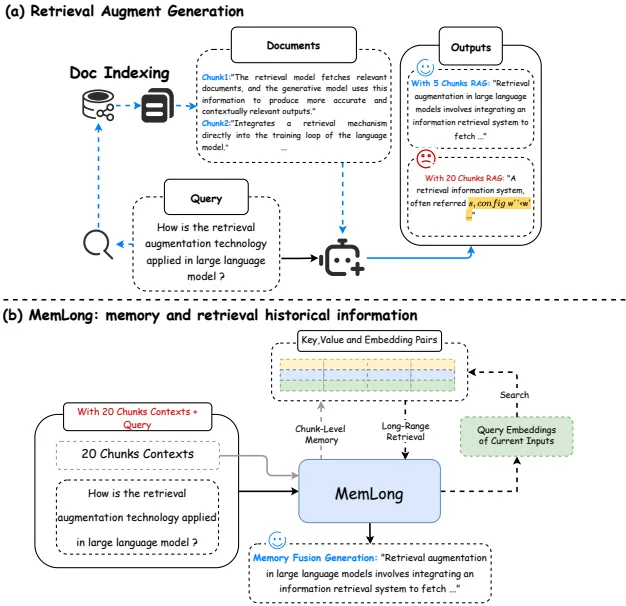
这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。
马斯克又搞出了一个超级厉害的东西——人工智能训练集群Colossus!

近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。

训练数据的质量优劣,直接影响人工智能(AI)大模型的能力水平。