

深度揭秘:Meta工程师如何构建超大规模AI训练网络?
深度揭秘:Meta工程师如何构建超大规模AI训练网络?最近,Meta的多个工程团队联合发表了一篇论文,描述了在引入基于GPU的分布式训练时,他们如何为其「量身定制」专用的数据中心网络。
来自主题: AI技术研报
9440 点击 2024-08-29 16:10
最近,Meta的多个工程团队联合发表了一篇论文,描述了在引入基于GPU的分布式训练时,他们如何为其「量身定制」专用的数据中心网络。

近日,HuggingFace开源了低成本AI机器人LeRobot,并指导大家从头开始构建AI控制的机器人,包括组装、配置到训练控制机器人的神经网络。
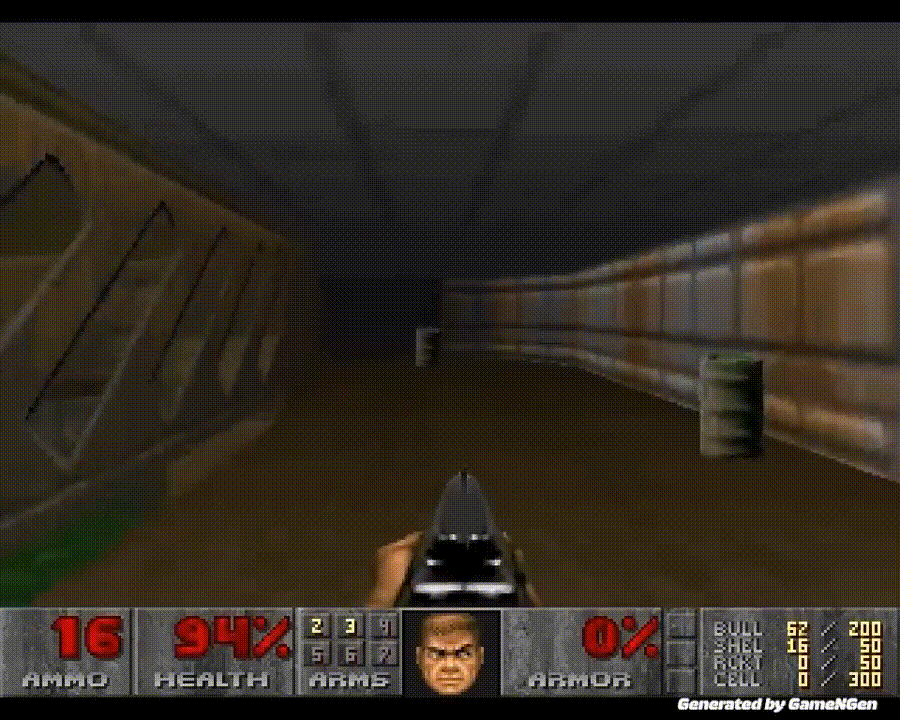
炸裂!世界上首个完全由AI驱动的游戏引擎来了。谷歌研究者训练的GameNGen,能以每秒20帧实时生成DOOM的游戏画面,画面如此逼真,60%的片段都没让玩家认出是AI!全球2000亿美元的游戏行业,从此将被改变。

OpenAI又憋大招了!据悉,下一代旗舰模型GPT-5或名为「猎户座」,由「草莓」合成的数据训练。而草莓具有极强的复杂推理(数学、编程)和语言能力,或将超越当前的任何模型的推理和生成的能力。

EasyRec利用语言模型的语义理解能力和协同过滤技术,提升了在零样本学习场景下的推荐性能。通过整合用户和物品的文本描述,EasyRec能够生成高质量的语义嵌入,实现个性化且适应性强的推荐。

来自复旦大学视觉与学习实验室的研究者们提出了一种新型的面向视频模型的对抗攻击方法 - 基于扩散模型的视频非限制迁移攻击(ReToMe-VA)。该方法采用逐时间步对抗隐变量优化策略,以实现生成对抗样本的空间不可感知性;同时,在生成对抗帧的去噪过程中引入了递归 token 合并策略,通过匹配及合并视频帧之间的自注意力 token,显著提升了对抗视频的迁移性和时序一致性。
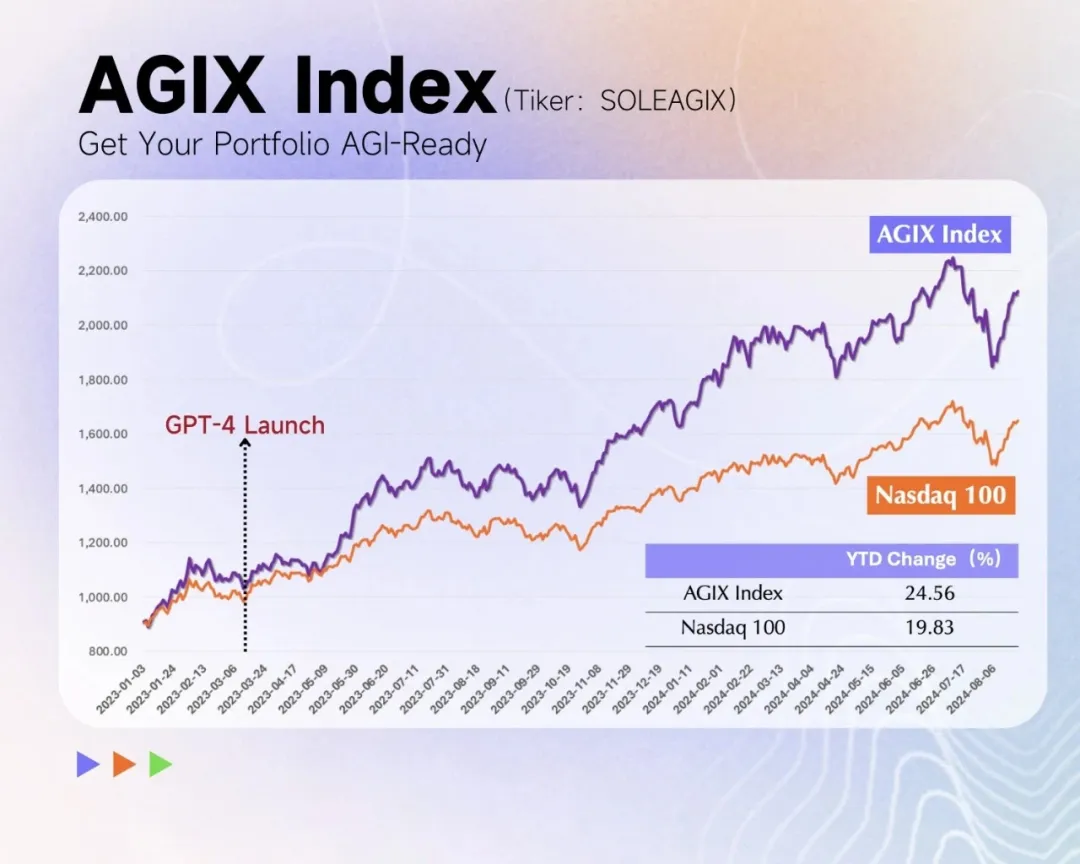
AGI 正在迎来新范式,RL 是 LLM 的秘密武器。

计算机是二进制的世界,所以浮点数也是用二进制来表示的,与整型不同的是,浮点数通过3个区间来表示:
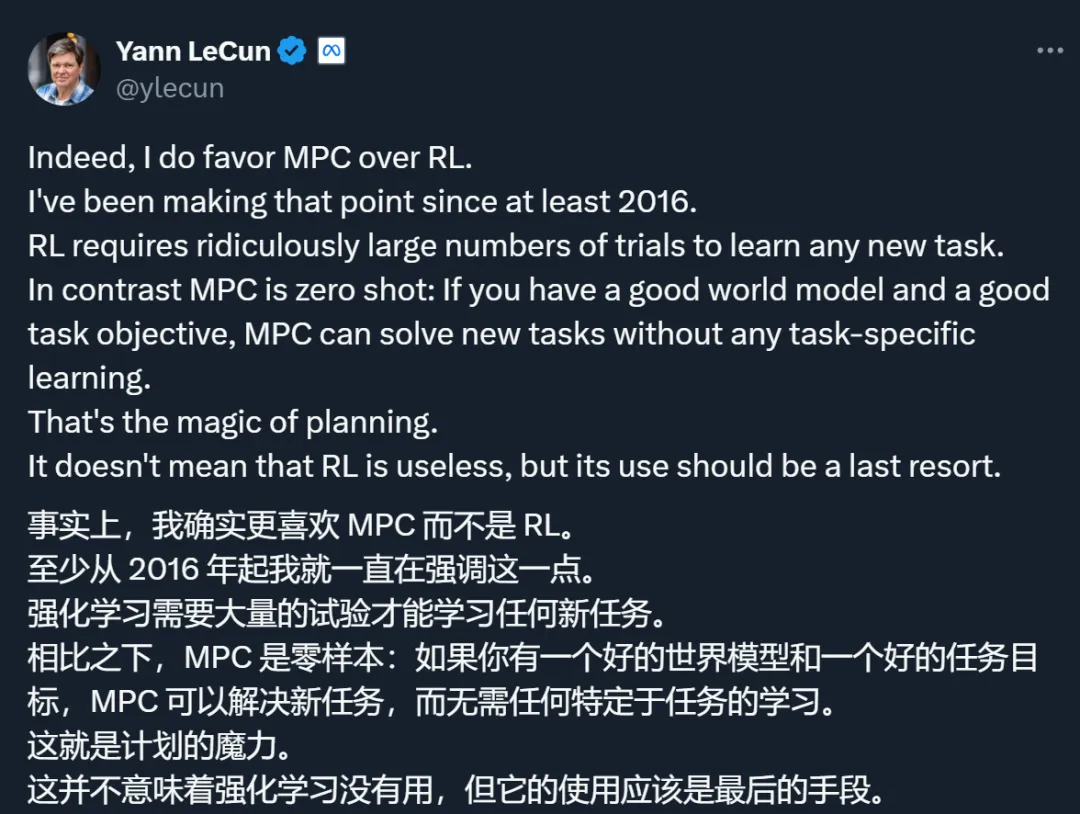
「相比于强化学习(RL),我确实更喜欢模型预测控制(MPC)。至少从 2016 年起,我就一直在强调这一点。强化学习在学习任何新任务时都需要进行极其大量的尝试。相比之下,模型预测控制是零样本的:如果你有一个良好的世界模型和一个良好的任务目标,模型预测控制就可以在不需要任何特定任务学习的情况下解决新任务。这就是规划的魔力。这并不意味着强化学习是无用的,但它的使用应该是最后的手段。」
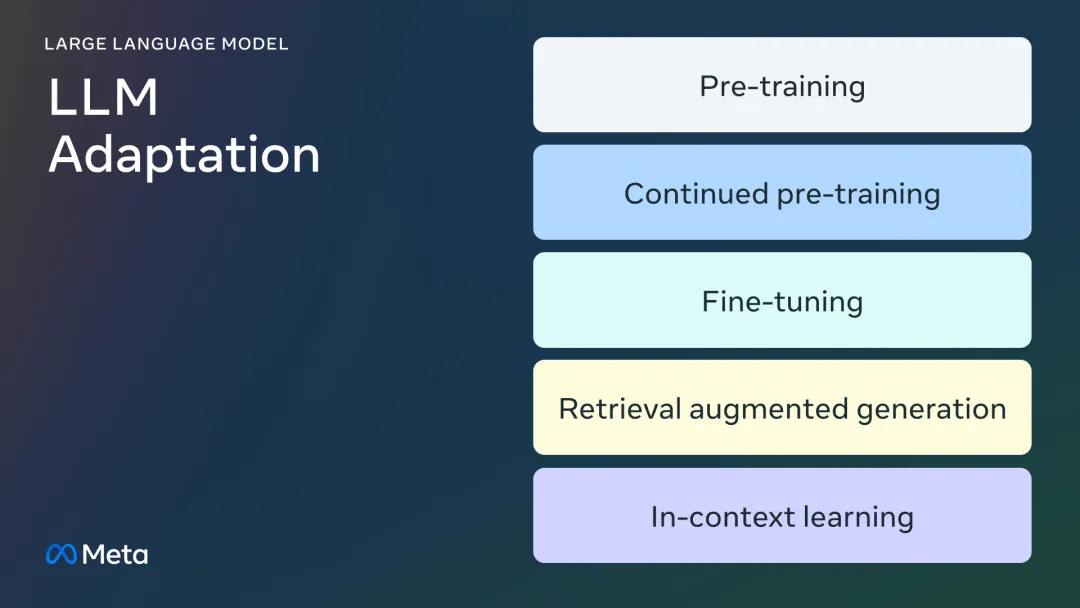
微调的所有门道,都在这里了。