

1890美元,就能从头训练一个还不错的12亿参数扩散模型
1890美元,就能从头训练一个还不错的12亿参数扩散模型只用1890美元、3700 万张图像,就能训练一个还不错的扩散模型。
来自主题: AI技术研报
10138 点击 2024-07-29 20:28
只用1890美元、3700 万张图像,就能训练一个还不错的扩散模型。

适逢Llama 3.1模型刚刚发布,英伟达就发表了一篇技术博客,手把手教你如何好好利用这个强大的开源模型,为领域模型或RAG系统的微调生成合成数据。
在Meta的Llama 3.1训练过程中,其运行的1.6万个GPU训练集群每3小时就会出现一次故障,意外故障中的半数都是由英伟达H100 GPU和HBM3内存故障造成的。
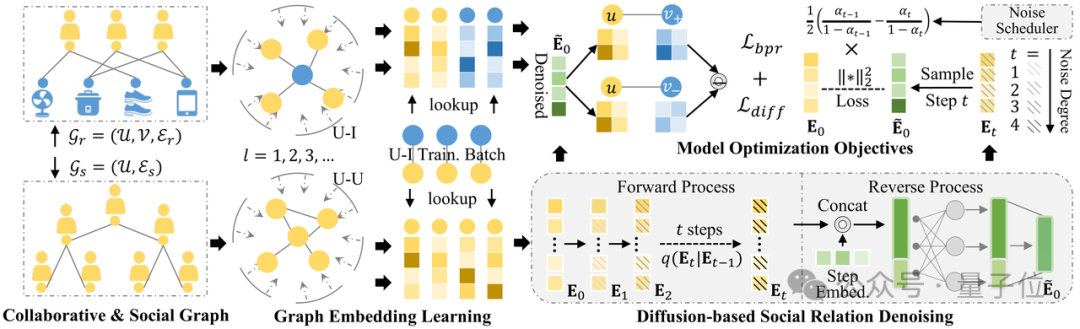
用扩散模型搞社交信息推荐,怎么解决数据噪声难题?现有的一些自监督学习方法效果还是有限。

每3个小时1次、平均1天8次,Llama 3.1 405B预训练老出故障,H100是罪魁祸首?

解决问题:语言智能体的动作通常由 Token(令牌,语言模型中表示单词/短语/汉字的最小符号单元)序列组成,直接将强化学习用于语言智能体进行策略优化的过程中,一般需要预定义可行动作集合,同时忽略了动作内 Token 细粒度信用分配问题,团队将 Agent 优化从动作层分解到 Token 层,为每个动作内 Token 提供更精细的监督,可在语言动作空间不受约束的环境中实现可控优化复杂度

一半以上的故障都归因于 GPU 及其高带宽内存。

已在多家头部大模型厂商的预训练流程中使用。

自回归训练方式已经成为了大语言模型(LLMs)训练的标准模式, 今天介绍一篇来自阿联酋世界第一所人工智能大学MBZUAI的VILA实验室和CMU计算机系合作的论文,题为《FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation》

最近,Latent Space发布的播客节目中请来了Meta的AI科学家Thomas Scialom。他在节目中揭秘了Llama 3.1的一些研发思路,并透露了后续Llama 4的更新方向。