
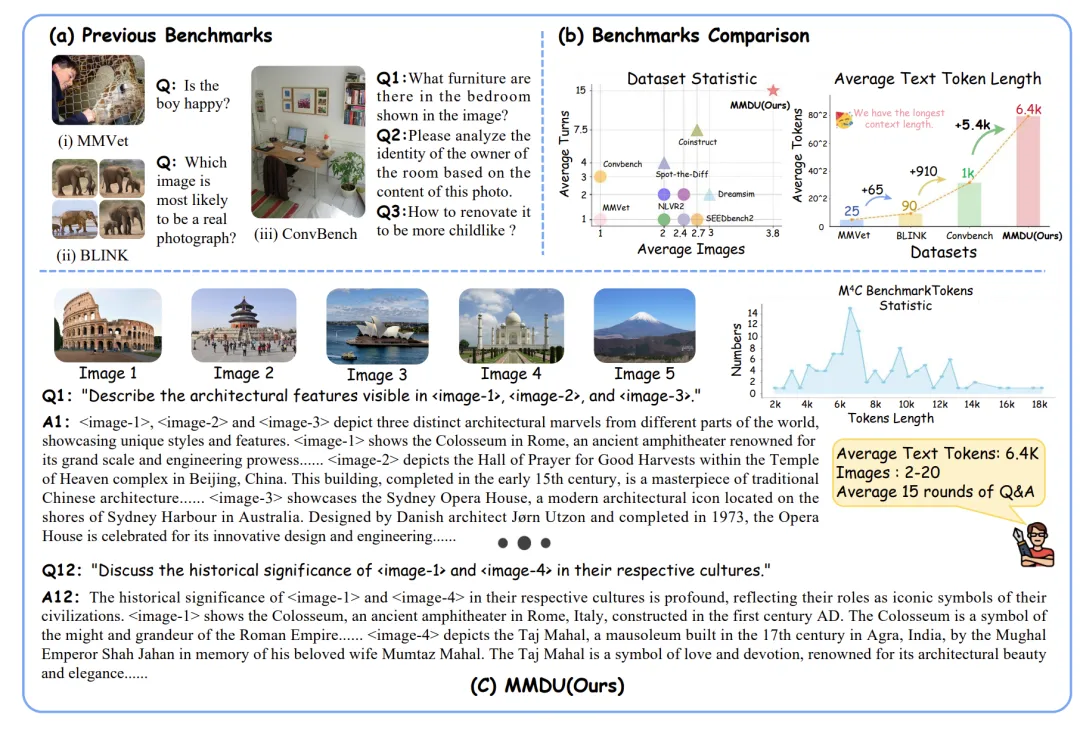
一次可输入多张图像,还能多轮对话!最新开源数据集,让AI聊天更接近现实
一次可输入多张图像,还能多轮对话!最新开源数据集,让AI聊天更接近现实大模型对话能更接近现实了!
来自主题: AI资讯
12321 点击 2024-06-30 12:42
大模型对话能更接近现实了!

文章第一作者为来自北京大学物理学院、即将加入人工智能研究院读博的胡逸。胡逸的导师为北京大学人工智能研究院助理教授、北京通用人工智能研究院研究员张牧涵,主要研究方向为图机器学习和大模型的推理和微调。
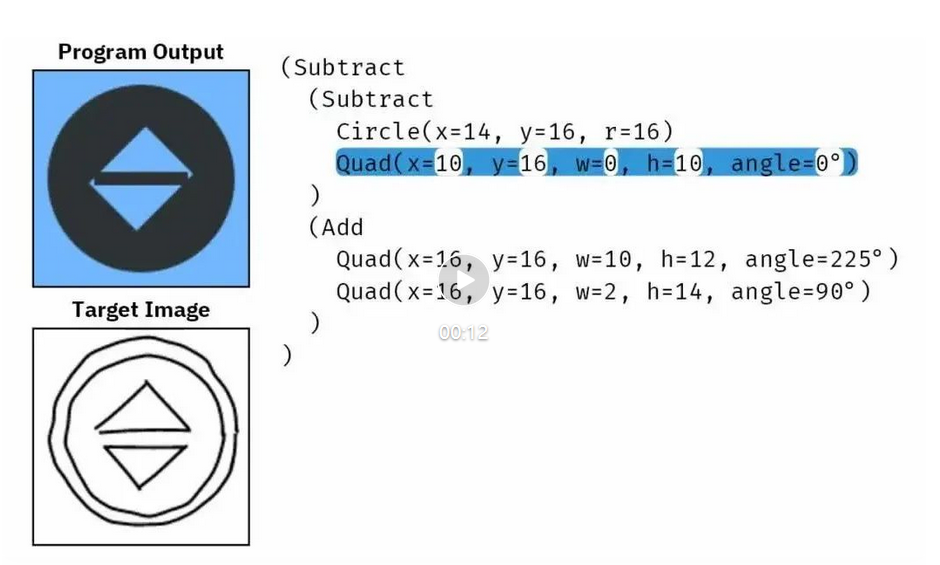
事实证明,扩散模型不仅能用于生成图像和视频,也能用于合成新程序。

本文提出了解决一般性编辑任务的统一框架!近期,复旦大学 FVL 实验室和南洋理工大学的研究人员对于多模态引导的基于文生图大模型的图像编辑算法进行了总结和回顾。综述涵盖 300 多篇相关研究,调研的最新模型截止至今年 6 月!

在这个数据为王的时代,数据是人工智能的三大支柱之一,其重要性不言而喻。最近,OpenAI 收购了数据库初创公司 Rockset,迅速引起了业内外的广泛关注。OpenAI 早已在算法和计算能力方面遥遥领先,通过这次战略性的收购,OpenAI 将在其产品中融合 Rockset 的先进数据索引和查询技术,帮助 OpenAI 将数据转化为 “可操作智能”。

本文将为大家介绍CVPR 2024 Highlight的论文LangSplat: 3D Language Gaussian Splatting(三维语义高斯泼溅)。LangSplat在开放文本目标定位和语义分割任务上达到SOTA性能。在1440×1080分辨率的图像上,查询速度比之前的SOTA方法LERF快了199倍。代码已开源。
今天,OpenAI悄悄在博客上发布了一篇新论文——CriticGPT,而这也是前任超级对齐团队的「遗作」之一。CriticGPT同样基于GPT-4训练,但目的却是用来指正GPT-4的输出错误,实现「自我批评」。

在当今的多模态大模型的发展中,模型的性能和训练数据的质量关系十分紧密,可以说是 “数据赋予了模型的绝大多数能力”。

上下文学习 (in-context learning, 简写为 ICL) 已经在很多 LLM 有关的应用中展现了强大的能力,但是对其理论的分析仍然比较有限。人们依然试图理解为什么基于 Transformer 架构的 LLM 可以展现出 ICL 的能力。
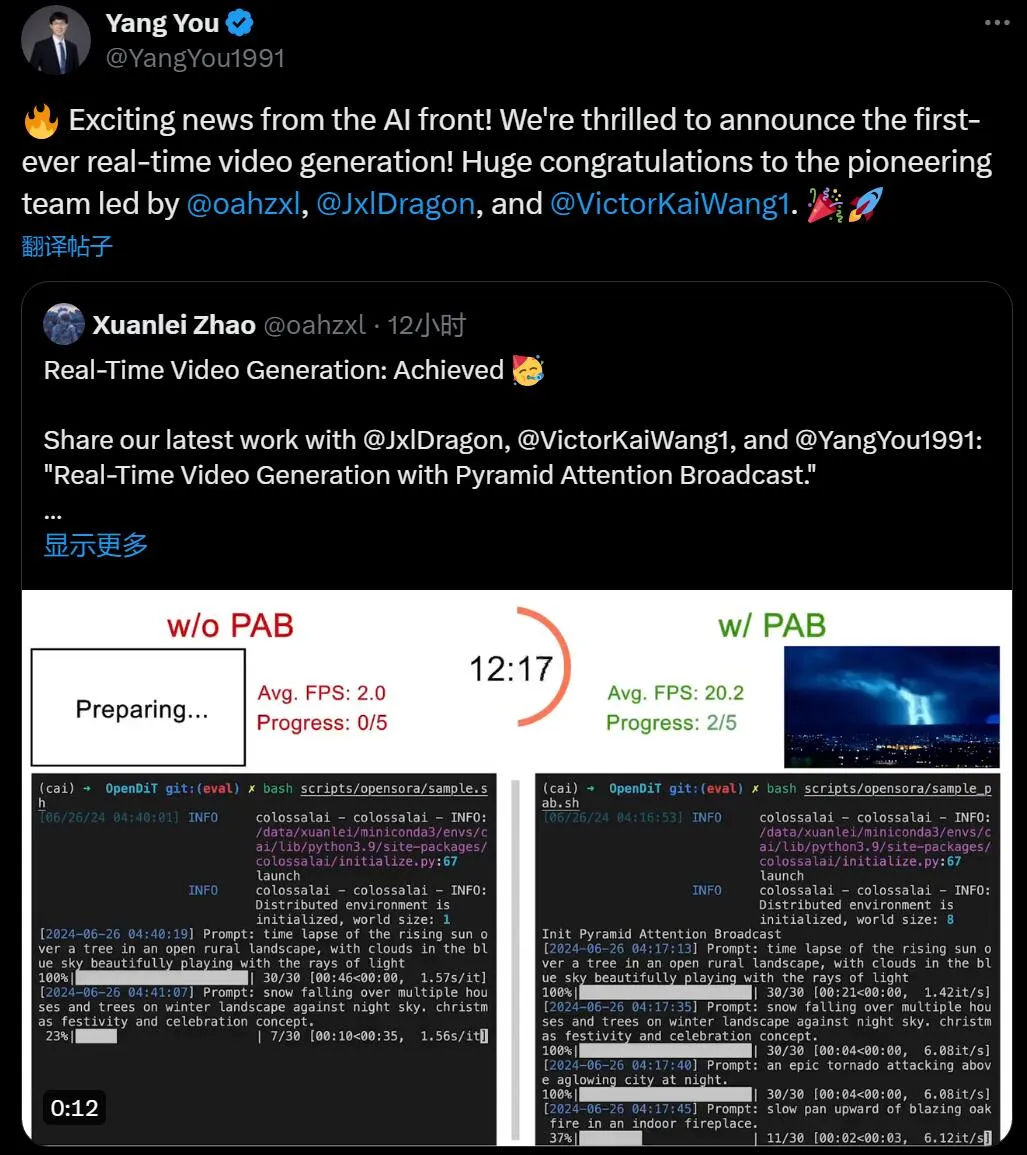
DiT 都能用,生成视频无质量损失,也不需要训练。