
从高考到奥林匹克竞技场:大模型与人类智能的终极较量
从高考到奥林匹克竞技场:大模型与人类智能的终极较量图灵奖得主Hinton在他的访谈中提及「在未来20年内,AI有50%的概率超越人类的智能水平」,并建议各大科技公司早做准备,而评定大模型(包括多模态大模型)的「智力水平」则是这一准备的必要前提。
来自主题: AI资讯
4687 点击 2024-06-21 13:15
图灵奖得主Hinton在他的访谈中提及「在未来20年内,AI有50%的概率超越人类的智能水平」,并建议各大科技公司早做准备,而评定大模型(包括多模态大模型)的「智力水平」则是这一准备的必要前提。

为了实现高精度的区域级多模态理解,本文提出了一种动态分辨率方案来模拟人类视觉认知系统。
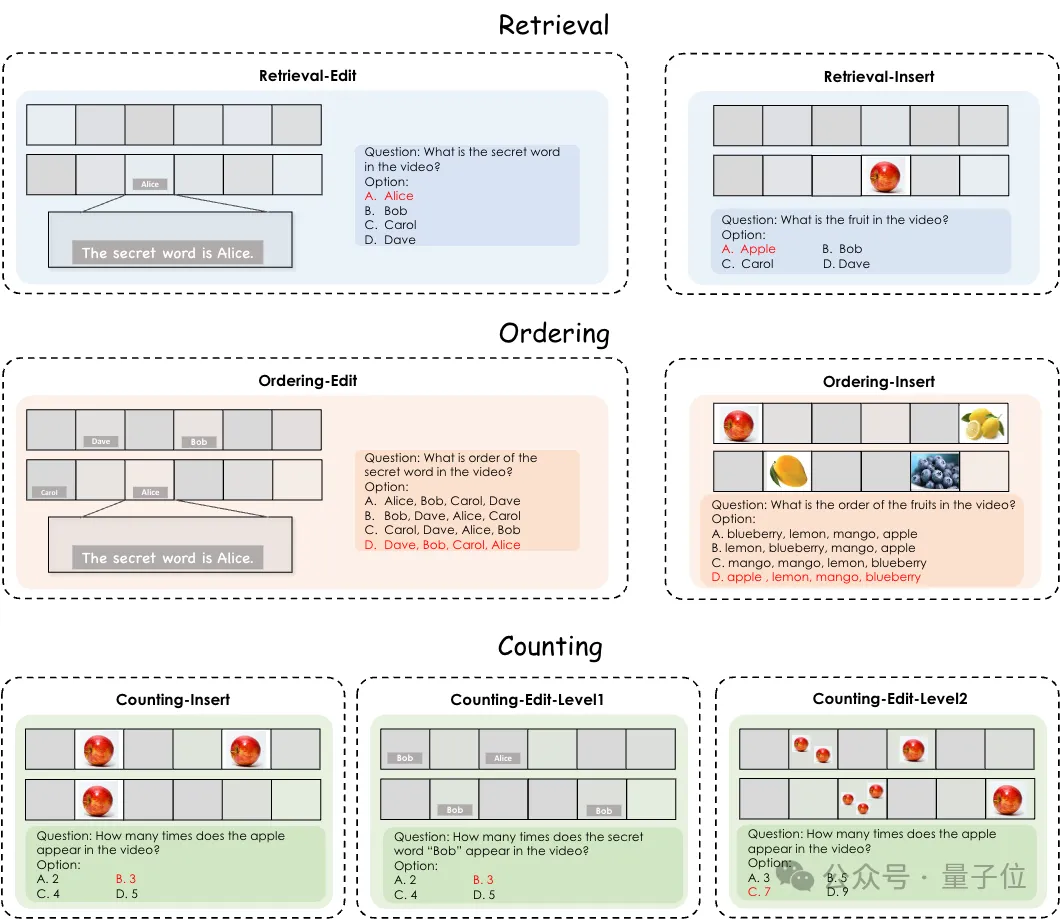
测试Gemini1.5 Pro、GPT-4o等多模态大模型的新基准来了,针对视频理解能力的那种。

拯救4bit扩散模型精度,仅需时间特征维护——以超低精度量化技术重塑图像内容生成!
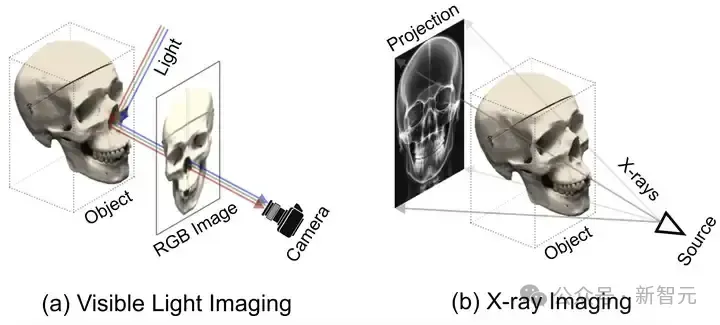
SAX-NeRF框架,一种专为稀疏视角下X光三维重建设计的新型NeRF方法,通过Lineformer Transformer和MLG采样策略显著提升了新视角合成和CT重建的性能。研究者还建立了X3D数据集,并开源了代码和预训练模型,为X光三维重建领域的研究提供了宝贵的资源和工具。

16秒720p高清视频,现在人人可免费一键生成!

基于 Transformer架构的大型语言模型在各种基准测试中展现出优异性能,但数百亿、千亿乃至万亿量级的参数规模会带来高昂的服务成本。例如GPT-3有1750亿参数,采用FP16存储,模型大小约为350GB,而即使是英伟达最新的B200 GPU 内存也只有192GB ,更不用说其他GPU和边缘设备。

通过高保真合成语音与真人语音无异。

本⽂介绍由清华等⾼校联合推出的⾸个开源的⼤模型⽔印⼯具包 MarkLLM。MarkLLM 提供了统⼀的⼤模型⽔印算法实现框架、直观的⽔印算法机制可视化⽅案以及系统性的评估模块,旨在⽀持研究⼈员⽅便地实验、理解和评估最新的⽔印技术进展。通过 MarkLLM,作者期望在给研究者提供便利的同时加深公众对⼤模型⽔印技术的认知,推动该领域的共识形成,进⽽促进相关研究的发展和推⼴应⽤。

在现实世界的机器学习应用中,随时间变化的分布偏移是常见的问题。这种情况被构建为时变域泛化(EDG),目标是通过学习跨领域的潜在演变模式,并利用这些模式,使模型能够在时间变化系统中对未见目标域进行良好的泛化。然而,由于 EDG 数据集中时间戳的数量有限,现有方法在捕获演变动态和避免对稀疏时间戳的过拟合方面遇到了挑战,这限制了它们对新任务的泛化和适应性。