

新架构Mamba更新二代!作者:别争了,数学上Transformer和SSM是一回事
新架构Mamba更新二代!作者:别争了,数学上Transformer和SSM是一回事Transformer挑战者、新架构Mamba,刚刚更新了第二代:
来自主题: AI技术研报
11718 点击 2024-06-04 16:13
Transformer挑战者、新架构Mamba,刚刚更新了第二代:

华南理工大学和香港大学的研究人员在ICML 2024上提出了一个简单而通用的时空提示调整框架FlashST,通过轻量级的时空提示网络和分布映射机制,使预训练模型能够适应不同的下游数据集特征,显著提高了模型在多种交通预测场景中的泛化能力。
在开源社区引起「海啸」的Mamba架构,再次卷土重来!这次,Mamba-2顺利拿下ICML。通过统一SSM和注意力机制,Transformer和SSM直接成了「一家亲」,Mamba-2这是要一统江湖了?

一般而言,训练神经网络耗费的计算量越大,其性能就越好。在扩大计算规模时,必须要做个决定:是增多模型参数量还是提升数据集大小 —— 必须在固定的计算预算下权衡此两项因素。

如何突破 Transformer 的 Attention 机制?中国科学院大学与鹏城国家实验室提出基于热传导的视觉表征模型 vHeat。将图片特征块视为热源,并通过预测热传导率、以物理学热传导原理提取图像特征。相比于基于Attention机制的视觉模型, vHeat 同时兼顾了:计算复杂度(1.5次方)、全局感受野、物理可解释性。

Scaling law发展到最后,可能每个人都站在一个数据孤岛上。
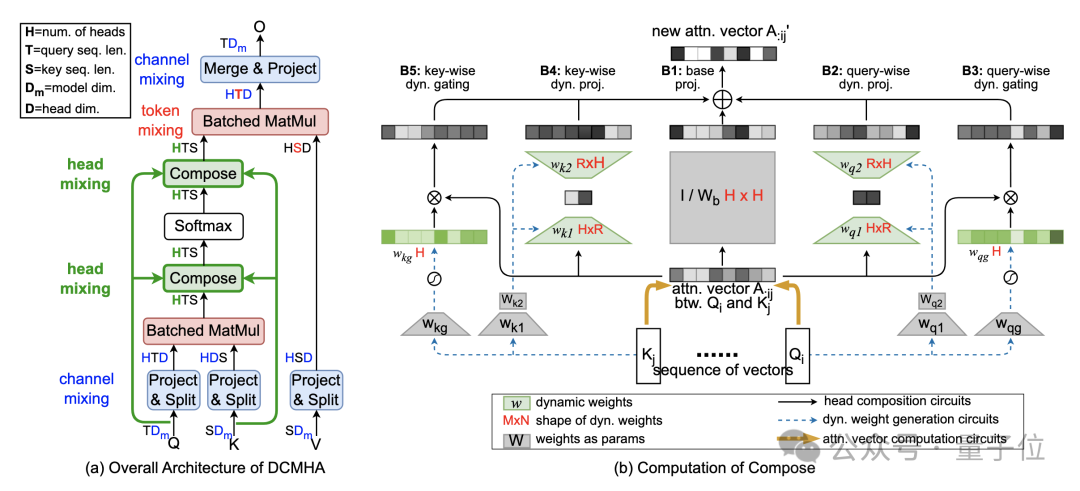
改进Transformer核心机制注意力,让小模型能打两倍大的模型!

研究人员提出了一种新的大型语言模型训练方法,通过一次性预测多个未来tokens来提高样本效率和模型性能,在代码和自然语言生成任务上均表现出显著优势,且不会增加训练时间,推理速度还能提升至三倍。

在以英语为主的语料库上训练的多语言LLM,是否使用英语作为内部语言?对此,来自EPFL的研究人员针对Llama 2家族进行了一系列实验。

刚刚,老黄又高调向全世界秀了一把:已经量产的Blackwell,8年内将把1.8万亿参数GPT-4的训练能耗狂砍到1/350;英伟达惊人的产品迭代,直接原地冲破摩尔定律;Blackwell的后三代路线图,也一口气被放出。