

Nature深度:大模型如何“赋能”机器人?机器人又如何“训练”大模型?
Nature深度:大模型如何“赋能”机器人?机器人又如何“训练”大模型?未来,会发生什么?
来自主题: AI资讯
9053 点击 2024-05-31 10:34
未来,会发生什么?

在当今数字化时代,3D 资产在元宇宙的建构、数字孪生的实现以及虚拟现实和增强现实的应用中扮演着重要角色,促进了技术创新和用户体验的提升。

高质量图像编辑的方法有很多,但都很难准确表达出真实的物理世界。 那么,Edit the World试试。
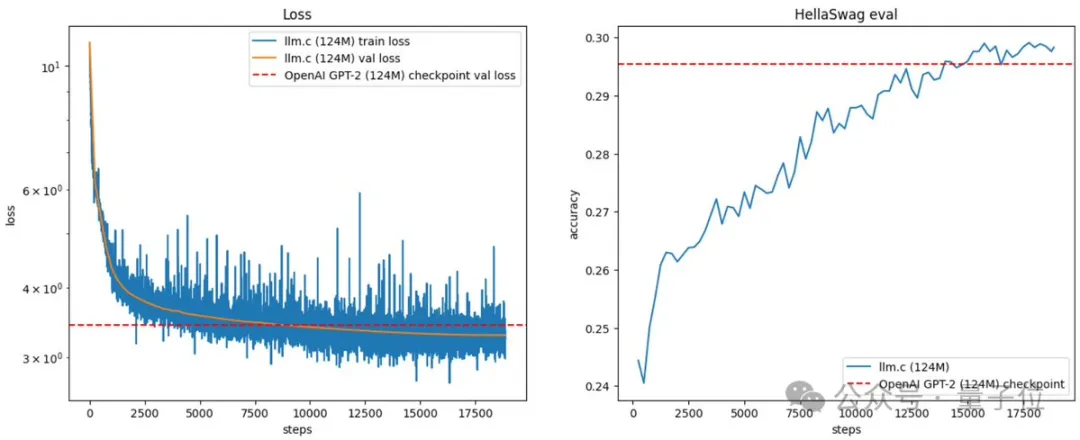
大神Karpathy已经不满足于用C语言造Llama了! 他给自己的最新挑战:复现OpenAI经典成果,从基础版GPT-2开始。

在大模型实际部署落地的过程中,如何赋予大模型持续学习的能力是一个至关重要的挑战。这使其能够动态适应新的任务并不断获得新的知识。大模型的持续学习主要面临两个重大挑战,分别是灾难性遗忘和知识迁移。灾难性遗忘是指模型在学习新任务时,会忘记其已掌握的旧任务。知识迁移则涉及到如何在学习新任务时有效地应用旧任务的知识来提升新任务学习的效果。
OpenAI 开始训练下一个前沿模型了。在联合创始人、首席科学家 Ilya Sutskever 官宣离职、超级对齐团队被解散之后,OpenAI 研究的安全性一直备受质疑。

斯坦福大学的研究人员研究了RAG系统与无RAG的LLM (如GPT-4)相比在回答问题方面的可靠性。研究表明,RAG系统的事实准确性取决于人工智能模型预先训练的知识强度和参考信息的正确性。

解散Ilya的超级对齐团队之后,奥特曼再造了一个新的「安全委员会」。OpenAI称正训练离AGI更近一步的下一代前沿模型,不过在这90天评估期间,怕是看不到新模型发布了。

多模态大模型,也有自己的CoT思维链了! 厦门大学&腾讯优图团队提出一种名为“领唱员(Cantor)”的决策感知多模态思维链架构,无需额外训练,性能大幅提升。
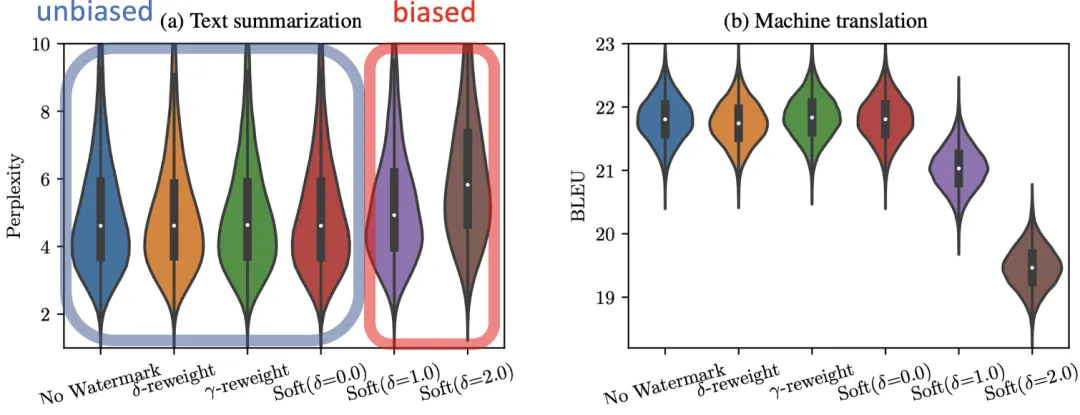
随着大语言模型(LLM)的快速发展,其在文本生成、翻译、总结等任务中的应用日益广泛。如微软前段时间发布的Copilot+PC允许使用者利用生成式AI进行团队内部实时协同合作,通过内嵌大模型应用,文本内容可能会在多个专业团队内部快速流转,对此,为保证内容的高度专业性和传达效率,同时平衡内容追溯、保证文本质量的LLM水印方法显得极为重要。