
LoRA数学编程任务不敌全量微调 | 哥大&Databricks新研究
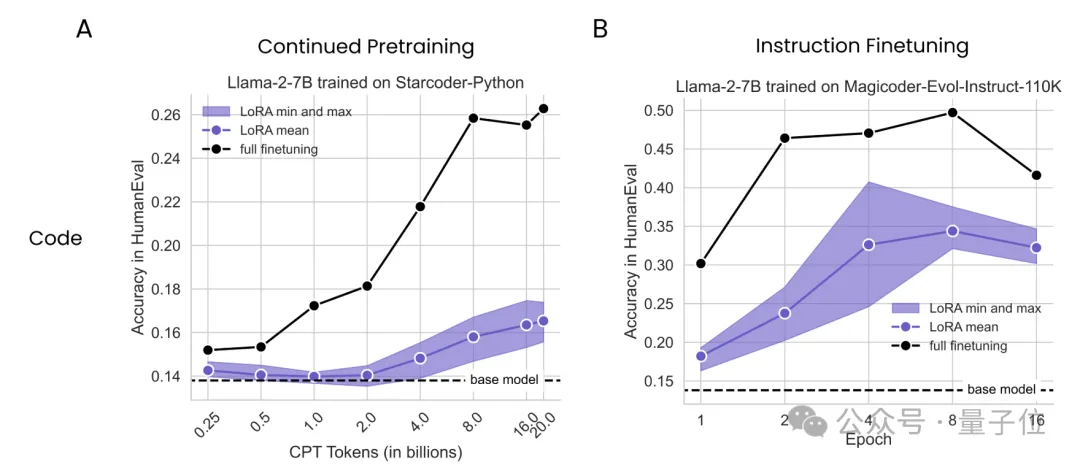
LoRA数学编程任务不敌全量微调 | 哥大&Databricks新研究大数据巨头Databricks与哥伦比亚大学最新研究发现,在数学和编程任务上,LoRA干不过全量微调。
来自主题: AI技术研报
4181 点击 2024-05-20 21:03
大数据巨头Databricks与哥伦比亚大学最新研究发现,在数学和编程任务上,LoRA干不过全量微调。

当计算预算低时,重复使用高质量数据更好;当不差钱时,使用大量数据更有利。

前几天,普林斯顿大学联合Meta在arXiv上发表了他们最新的研究成果——Lory模型,论文提出构建完全可微的MoE模型,是一种预训练自回归语言模型的新方法。

大语言模型可谓是迄今为止对人类行为最大的建模,如何借助大语言模型工具,让科技发展更好地应用到真实人类社会中去?从哈佛物理系到大语言模型结合社会学和经济学的研究,朱科航的思考路径,聚焦在对人类行为的深度学习和理解。在开始今天阅读之前,大家不妨先猜一猜,大语言模型之前人类应用最广的 TOP2 机器学习是什么?Enjoy

预训练语言模型在分析核苷酸序列方面显示出了良好的前景,但使用单个预训练权重集在不同任务中表现出色的多功能模型仍然存在挑战。

本月初,来自 MIT 等机构的研究者提出了一种非常有潜力的 MLP 替代方法 ——KAN。

在线和离线对齐算法的性能差距根源何在?DeepMind实证剖析出炉

GPT-4o发布不到一周,首个敢于挑战王者的新模型诞生!最近,Meta团队发布了「混合模态」Chameleon,可以在单一神经网络无缝处理文本和图像。10万亿token训练的34B参数模型性能接近GPT-4V,刷新SOTA。

“Scaling Law不是万金油”——关于大模型表现,华为又提出了新理论。

许多临床任务需要了解专业数据,例如医学图像、基因组学,这类专业知识信息在通用多模态大模型的训练中通常不存在。