

微调和量化竟会增加越狱风险!Mistral、Llama等无一幸免
微调和量化竟会增加越狱风险!Mistral、Llama等无一幸免大模型又又又被曝出安全问题!
来自主题: AI技术研报
10578 点击 2024-05-07 22:26
大模型又又又被曝出安全问题!

在机器学习和计算机视觉中,让机器准确地识别和理解手和物体之间的交互动作,那是相当费劲。

AI发展驱动收入增长,但成本激增需大投资。

过去几年,借助Scaling Laws的魔力,预训练的数据集不断增大,使得大模型的参数量也可以越做越大,从五年前的数十亿参数已经成长到今天的万亿级,在各个自然语言处理任务上的性能也越来越好。

Sora刚发布后没多久,火眼金睛的网友们就发现了不少bug,比如模型对物理世界知之甚少,小狗在走路的时候,两条前腿就出现了交错问题,让人非常出戏。 对于生成视频的真实感来说,物体的交互非常重要,但目前来说,合成真实3D物体在交互中的动态行为仍然非常困难。

如今的生成式AI在人工智能领域迅猛发展,在计算机视觉中,图像和视频生成技术已日渐成熟,如Midjourney、Stable Video Diffusion [1]等模型广泛应用。然而,三维视觉领域的生成模型仍面临挑战。

过去一年,AI大模型无疑是科技行业中最亮眼的主角,从FAAMG到BAT、再到一众初创企业,无数优秀的大脑、海量的资源都投入到了这个有望解放人类生产力的赛道中。

Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。
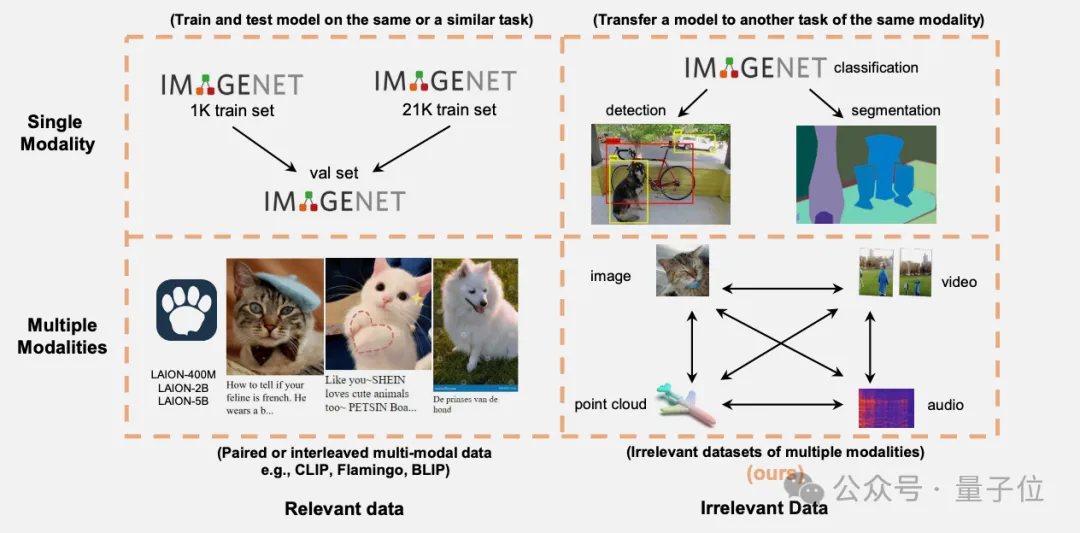
万万没想到,与任务无直接关联的多模态数据也能提升Transformer模型性能。

“预测下一个token”被认为是大模型的基本范式,一次预测多个tokens又会怎样?