

革命新架构掀翻Transformer!无限上下文处理,2万亿token碾压Llama 2
革命新架构掀翻Transformer!无限上下文处理,2万亿token碾压Llama 2继Mamba之后,又一敢于挑战Transformer的架构诞生了!
来自主题: AI技术研报
6025 点击 2024-04-17 19:23
继Mamba之后,又一敢于挑战Transformer的架构诞生了!

多任务机器人学习在应对多样化和复杂情景方面具有重要意义。然而,当前的方法受到性能问题和收集训练数据集的困难的限制
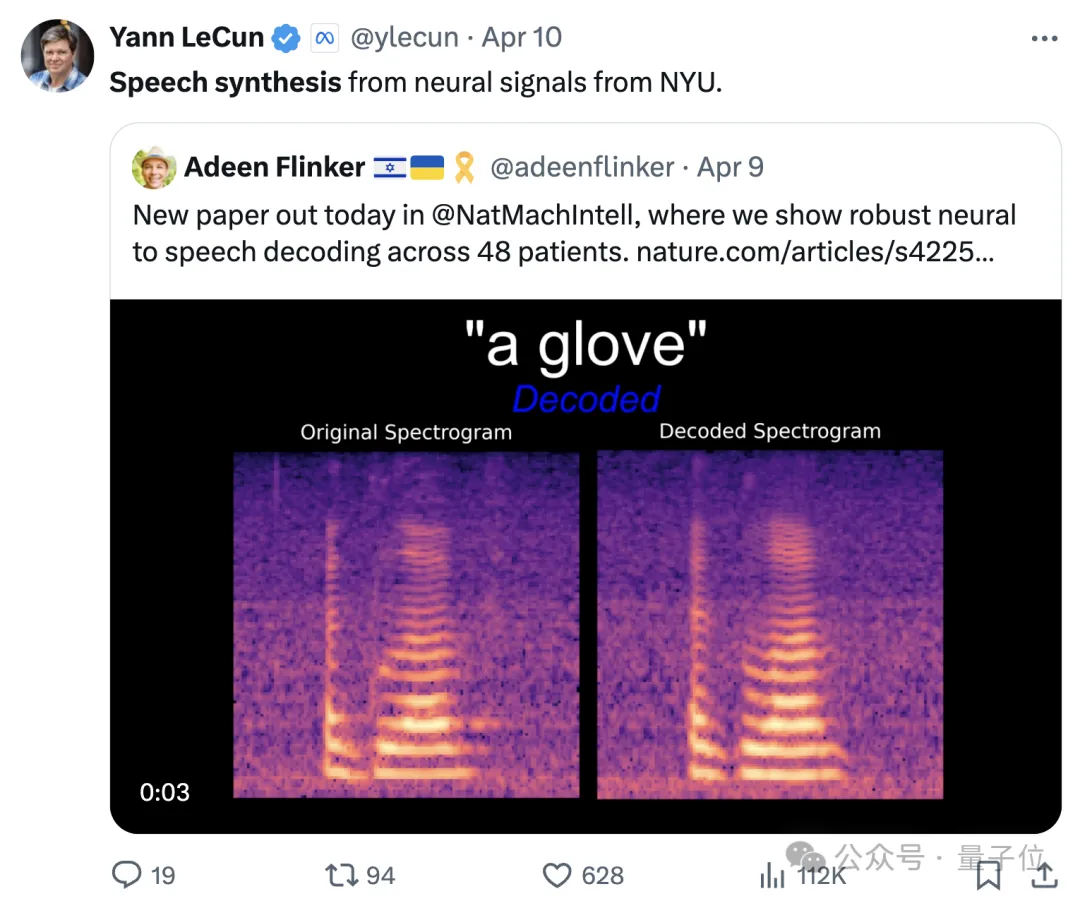
脑机接口最新进展登上Nature子刊,深度学习三巨头之一的LeCun都来转发。
最近,一则数据点出了AI领域算力需求的惊人增长—— 根据业内专家的预估,OpenAI推出的Sora在训练环节大约需要在4200-10500张NVIDIA H100上训练1个月,并且当模型生成到推理环节以后,计算成本还将迅速超过训练环节。

如何复盘大模型技术爆发的这一年?除了直观的感受,你还需要一份系统的总结

现今,机器学习(ML),更具体地说,深度学习已经改变了从金融到医疗等广泛的行业。在当前的 ML 范式中,训练数据首先被收集和策划,然后通过最小化训练数据上的某些损失标准来优化 ML 模型

从国际顶流 GPT-4 128K、Claude 200K 到国内「当红炸子鸡」支持 200 万字上下文的 Kimi Chat,大语言模型(LLM)在长上下文技术上不约而同地卷起来了

提出图像生成新范式,从预测下一个token变成预测下一级分辨率,效果超越Sora核心组件Diffusion Transformer(DiT

训练下一代万亿级参数大模型的高效芯片诞生了!

以神经网络为基础的深度学习技术已经在诸多应用领域取得了有效成果