

谷歌更新Transformer架构,更节省计算资源!50%性能提升
谷歌更新Transformer架构,更节省计算资源!50%性能提升谷歌终于更新了Transformer架构。最新发布的Mixture-of-Depths(MoD),改变了以往Transformer计算模式。它通过动态分配大模型中的计算资源,跳过一些不必要计算,显著提高训练效率和推理速度。
来自主题: AI技术研报
8279 点击 2024-04-05 17:04
谷歌终于更新了Transformer架构。最新发布的Mixture-of-Depths(MoD),改变了以往Transformer计算模式。它通过动态分配大模型中的计算资源,跳过一些不必要计算,显著提高训练效率和推理速度。

在探索人工智能边界时,我们时常惊叹于人类孩童的学习能力 —— 可以轻易地将他人的动作映射到自己的视角,进而模仿并创新。当我们追求更高阶的人工智能的时候,无非是希望赋予机器这种与生俱来的天赋。

3月29日,以“数据驱动,智绘未来”为主题的2024北京AI原生产业创新大会暨北京数据基础制度先行区成果发布会举办。会上,北京国际大数据交易所(以下简称“北数所”)牵头正式发布首批100个人工智能大模型高质量训练数据集,经联盟牵头推荐,中关村数字媒体产业联盟成员单位新华网、山东工艺美术学院、中国搜索、中文在线、北京服装学院、硅星人等院校、企业的高质量数据集入选。

就在刚刚,特斯拉CV负责人Ethan Knight被曝已经离职,转投xAI。网友纷纷猜测:马斯克这是要放弃特斯拉FSD了?他急忙澄清道:特斯拉在自动驾驶上正在拼命加速,而AI的人才争夺战,才是最疯狂的!

如果让你在互联网上给大模型选一本中文教材,你会去哪里取材?是知乎,是豆瓣,还是微博?一个研究团队为了构建高质量的中文指令微调数据集,对这些社交媒体进行了测试,想找到训练大模型最好的中文预料,结果答案保证让你大跌眼镜——
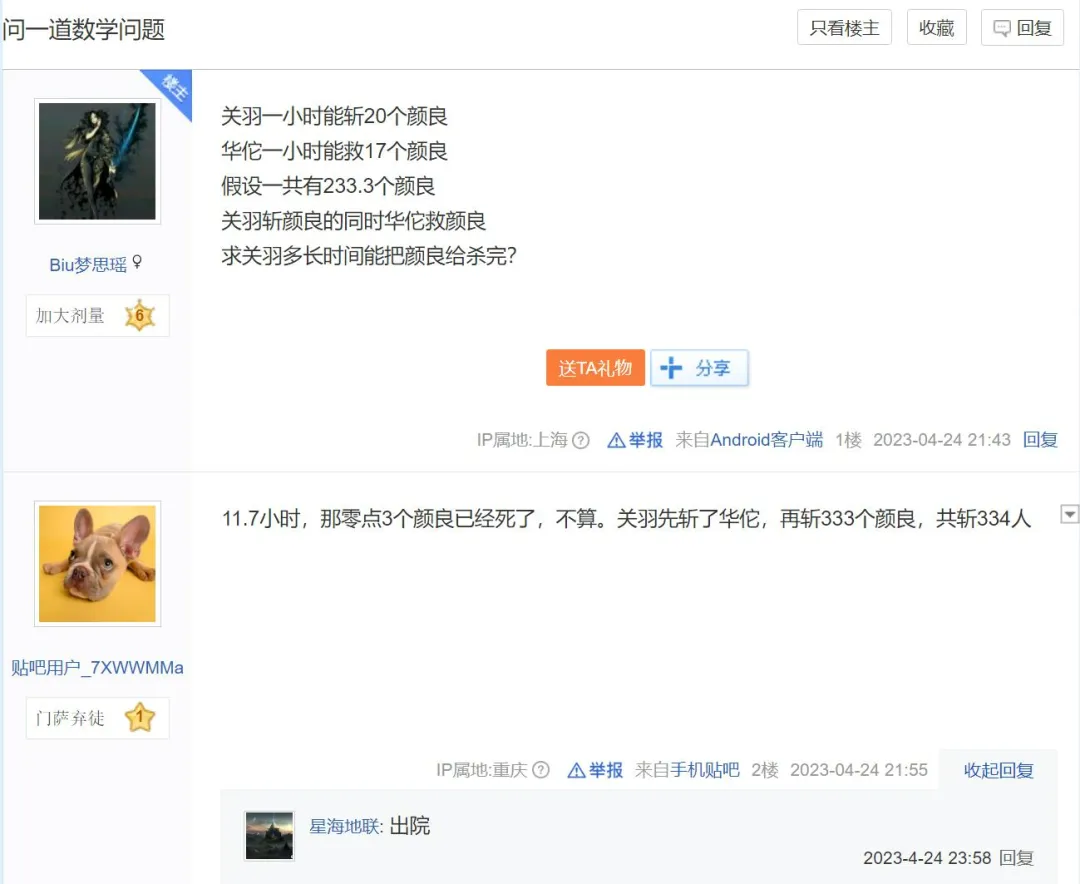
「被门夹过的核桃,还能补脑吗?」

物体姿态估计对于各种应用至关重要,例如机器人操纵和混合现实。实例级方法通常需要纹理 CAD 模型来生成训练数据,并且不能应用于测试时未见过的新物体;而类别级方法消除了这些假设(实例训练和 CAD 模型),但获取类别级训练数据需要应用额外的姿态标准化和检查步骤。

要不他们可能就跳槽到 OpenAI 了。当全球首富埃隆・马斯克(Elon Musk)建立 xAI,准备与 OpenAI、谷歌竞争大模型时,他必须与众多科技巨头、初创公司争夺人才。不过,他使用了一些取巧的办法:从自家的特斯拉挖来了几名优秀工程师。
离大谱了,弱智吧登上正经AI论文,还成了最好的中文训练数据??

基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。