

清华、哈工大把大模型压缩到了1bit,把大模型放在手机里跑的愿望就快要实现了!
清华、哈工大把大模型压缩到了1bit,把大模型放在手机里跑的愿望就快要实现了!近期,清华大学和哈尔滨工业大学联合发布了一篇论文:把大模型压缩到 1.0073 个比特时,仍然能使其保持约 83% 的性能!
来自主题: AI技术研报
9229 点击 2024-03-03 18:06
近期,清华大学和哈尔滨工业大学联合发布了一篇论文:把大模型压缩到 1.0073 个比特时,仍然能使其保持约 83% 的性能!

随着 Sora 的爆火,人们看到了 AI 视频生成的巨大潜力,对这一领域的关注度也越来越高。
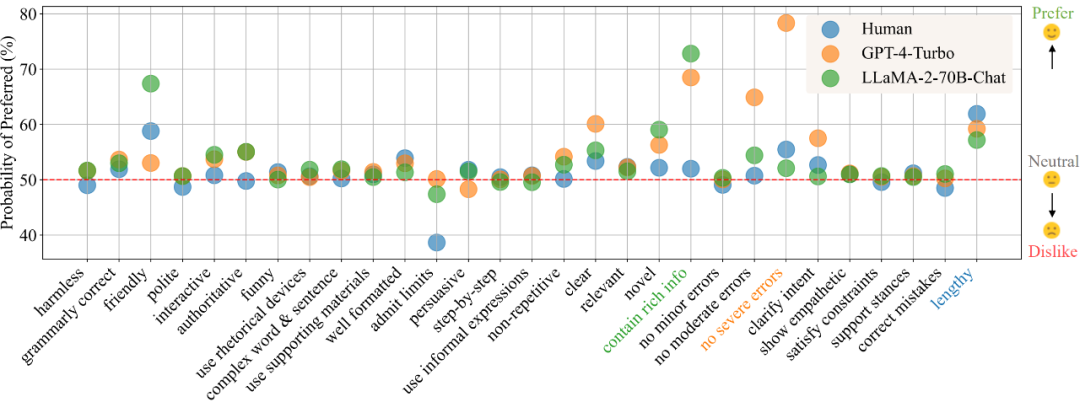
在目前的模型训练范式中,偏好数据的的获取与使用已经成为了不可或缺的一环。在训练中,偏好数据通常被用作对齐(alignment)时的训练优化目标,如基于人类或 AI 反馈的强化学习(RLHF/RLAIF)或者直接偏好优化(DPO),而在模型评估中,由于任务的复杂性且通常没有标准答案,则通常直接以人类标注者或高性能大模型(LLM-as-a-Judge)的偏好标注作为评判标准。

有人表示:「等待已久的 AI 图像创建功能终于迎来了图层!」
GPT早已成为大模型时代的基础。国外一位开发者发布了一篇实践指南,仅用60行代码构建GPT。
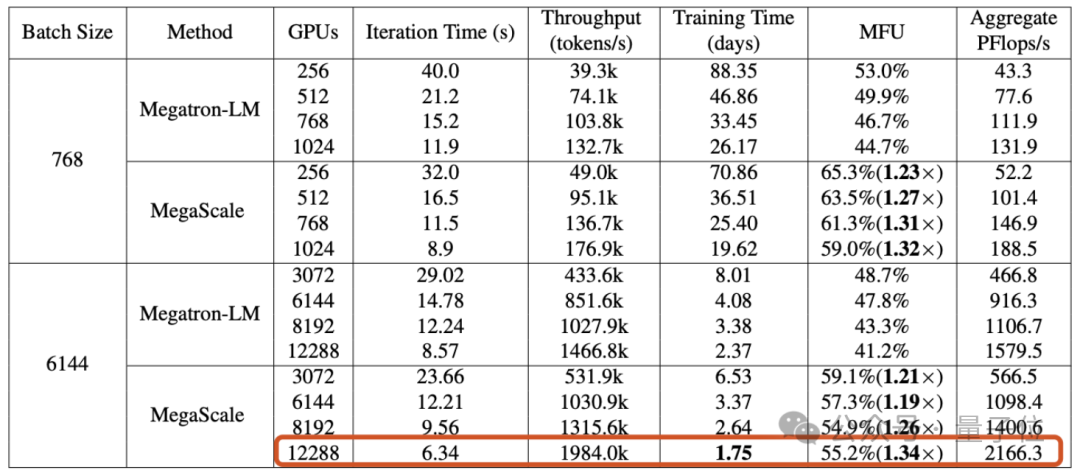
随着对Sora技术分析的展开,AI基础设施的重要性愈发凸显。
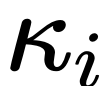
本文提出了扩散模型中UNet的long skip connection的scaling操作可以有助于模型稳定训练的分析,目前已被NeurIPS 2023录用。同时,该分析还可以解释扩散模型中常用但未知原理的1/√2 scaling操作能加速训练的现象。
根据 OpenAI 披露的技术报告,Sora 的核心技术点之一是将视觉数据转化为 patch 的统一表征形式,并通过 Transformer 和扩散模型结合,展现了卓越的扩展(scale)特性。
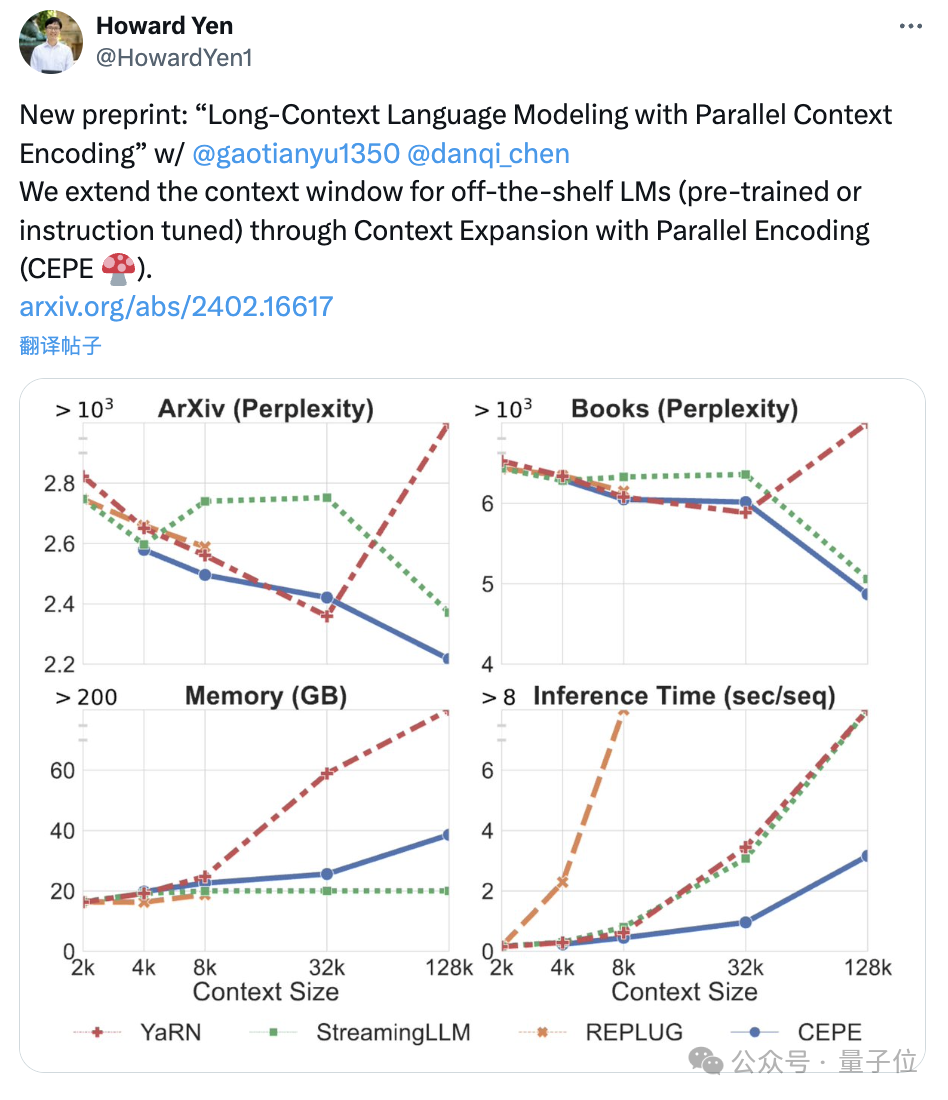
陈丹琦团队刚刚发布了一种新的LLM上下文窗口扩展方法:它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。

Reddit和OpenAI及谷歌,竟有着如此错综复杂的关系?最近,Reddit和谷歌双双官宣了一项6000万美元的合作协议,Reddit的数据将帮助谷歌训练AI模型。巧的是,Altman正是Reddit股东之一。