
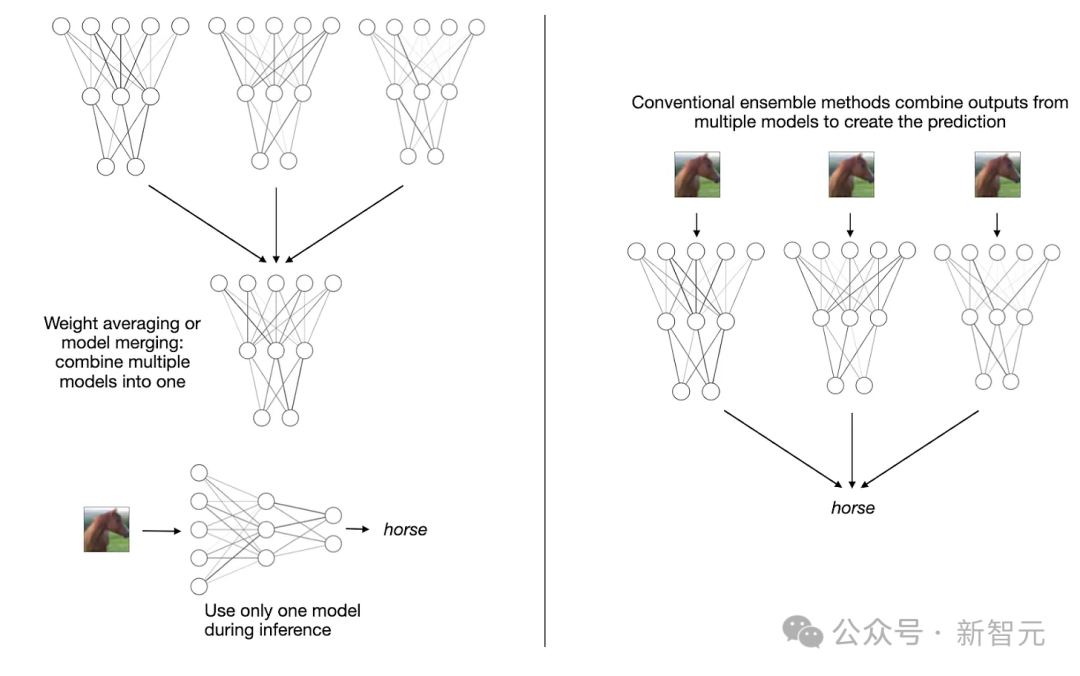
「大模型变小」成年度大趋势!1月AI四大研究精彩亮点超长总结,模型合并MoE方法是主流
「大模型变小」成年度大趋势!1月AI四大研究精彩亮点超长总结,模型合并MoE方法是主流AI大模型并非越大越好?过去一个月,关于大模型变小的研究成为亮点,通过模型合并,采用MoE架构都能实现小模型高性能。
来自主题: AI技术研报
6065 点击 2024-02-09 12:11
AI大模型并非越大越好?过去一个月,关于大模型变小的研究成为亮点,通过模型合并,采用MoE架构都能实现小模型高性能。
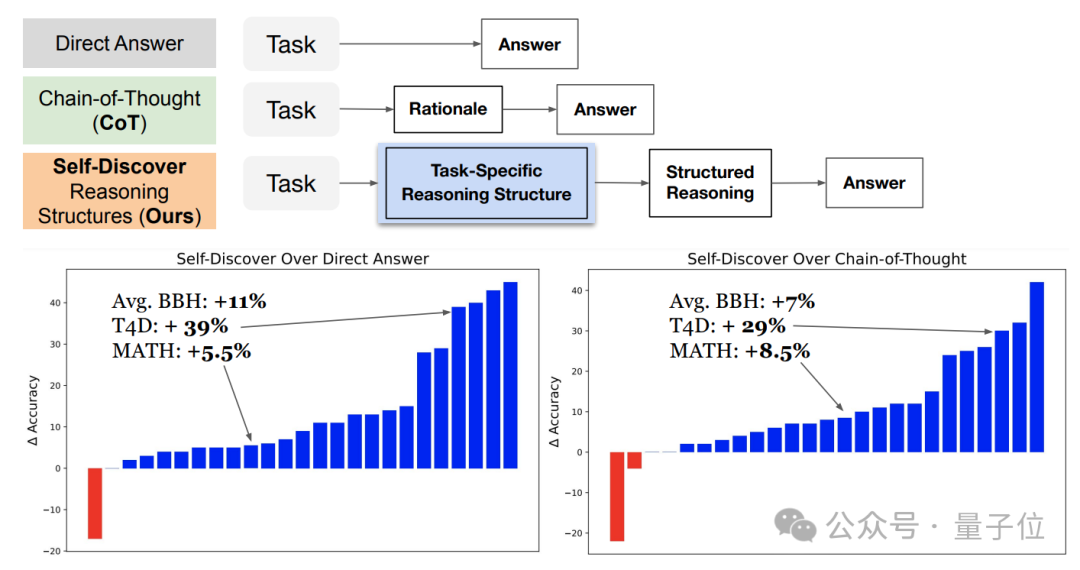
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。

在AI大模型初创企业普遍还处于入不敷出、疯狂烧钱的阶段时,一家专注于AI数据服务的初创企业已经赚得盆满钵满,成为收入最高的AI创业公司之一。

现有的语义分割技术在评估指标、损失函数等设计上都存在缺陷,研究人员针对相关缺陷设计了全新的损失函数、评估指标和基准,在多个应用场景下展现了更高的准确性和校准性。

今天,穆罕默德・本・扎耶德人工智能大学 VILA Lab 带来了一项关于如何更好地为不同规模的大模型书写提示词(prompt)的研究,让大模型性能在不需要任何额外训练的前提下轻松提升 50% 以上。该工作在 X (Twitter)、Reddit 和 LinkedIn 等平台上都引起了广泛的讨论和关注。
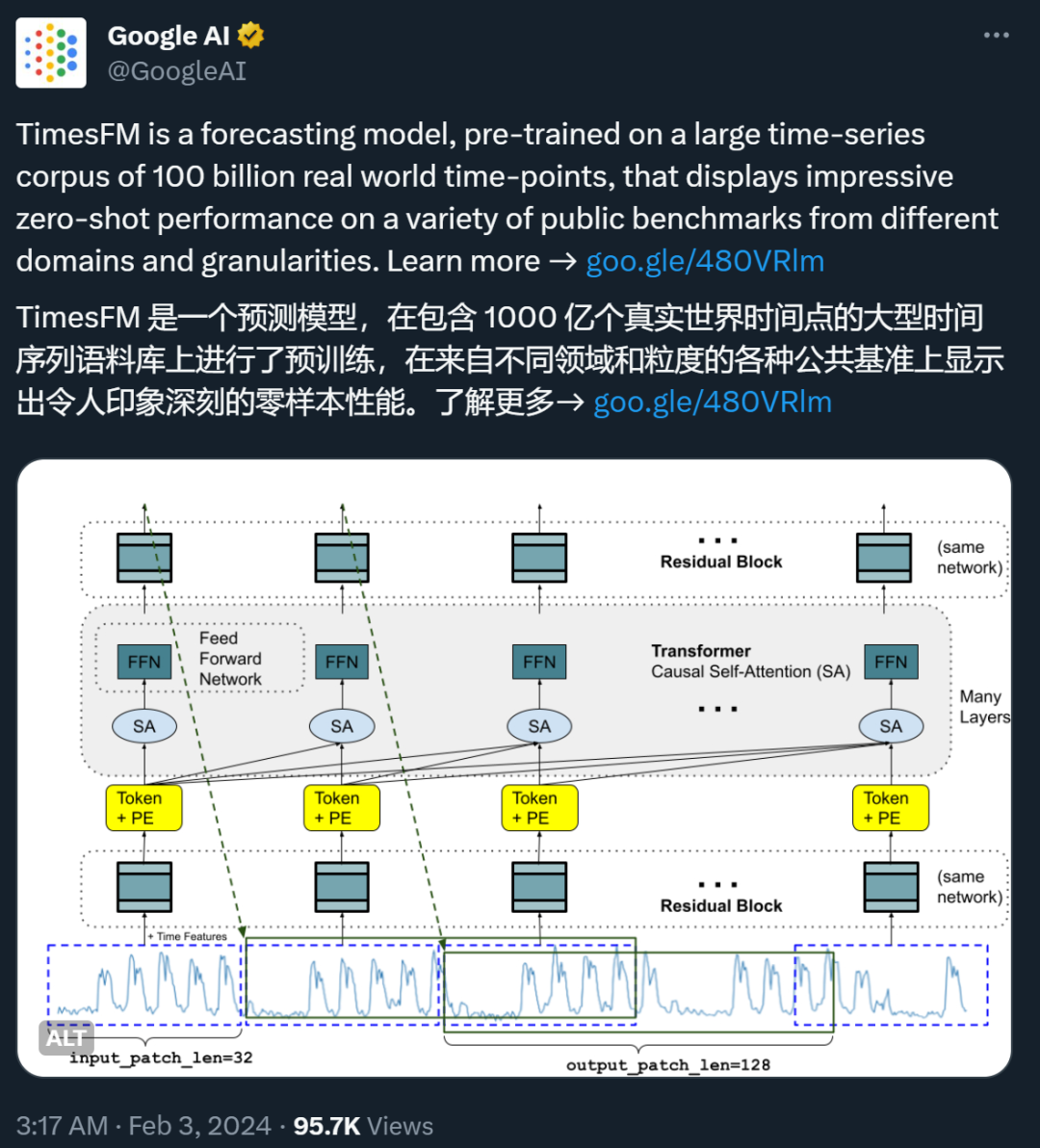
最近,谷歌的一篇论文在 X 等社交媒体平台上引发了一些争议。

前不久,美国商务部出了一份《采取额外措施应对与重大恶意网络行为相关的国家紧急状态》提案,提出:禁止中国公司使用美国的云计算资源来训练AI模型。这相当于AI芯片禁运的“补丁”。美国商务部长吉娜·雷蒙多在采访时提到,美国的云数据中心也大量使用AI芯片,而美国对芯片实施了出口管制,也必须考虑关闭这条路径。

模型通过学习这些 token 的上下文关系以及如何组合它们来表示原始文本或预测下一个 token。

2023 年 12 月,首个开源 MoE 大模型 Mixtral 8×7B 发布,在多种基准测试中,其表现近乎超越了 GPT-3.5 和 LLaMA 2 70B,而推理开销仅相当于 12B 左右的稠密模型。为进一步提升模型性能,稠密 LLM 常由于其参数规模急剧扩张而面临严峻的训练成本。

作为图领域首个通用框架,OFA实现了训练单一GNN模型即可解决图领域内任意数据集、任意任务类型、任意场景的分类任务。