

不要教一个AI学坏,因为它不会再学好
不要教一个AI学坏,因为它不会再学好最近,AI初创公司Anthropic的研究表明,一旦LLM学会了人类教授的欺骗行为,它们就会在训练和评估的过程中隐藏自己,并在使用时偷偷输出恶意代码、注入漏洞。
来自主题: AI资讯
8124 点击 2024-01-16 10:06
最近,AI初创公司Anthropic的研究表明,一旦LLM学会了人类教授的欺骗行为,它们就会在训练和评估的过程中隐藏自己,并在使用时偷偷输出恶意代码、注入漏洞。

图像到视频生成(I2V)任务旨在将静态图像转化为动态视频,这是计算机视觉领域的一大挑战。其难点在于从单张图像中提取并生成时间维度的动态信息,同时确保图像内容的真实性和视觉上的连贯性。大多数现有的 I2V 方法依赖于复杂的模型架构和大量的训练数据来实现这一目标。

本综述深入探讨了大型语言模型的资源高效化问题。
“耍心机”不再是人类的专利,大模型也学会了!经过特殊训练,它们就可以做到平时深藏不露,遇到关键词就毫无征兆地变坏。

世界上最快超算集群Frontier,用8%的GPU训练出了一个万亿级规模的大模型,而且是在AMD硬件平台之上完成。研究人员将训练的细节和克服的困难写成了一篇论文,展示了如何用非英伟达的生态完成大模型训练的技术框架和细节。
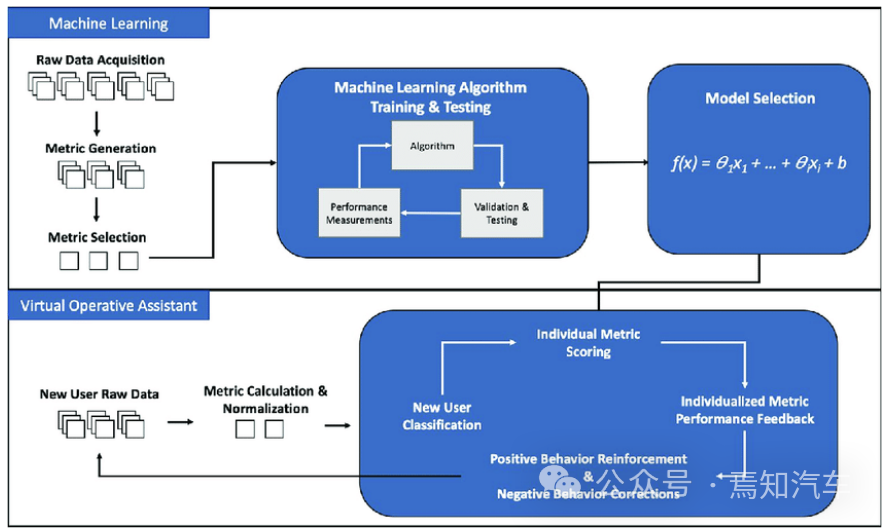
自动驾驶中的大模型处理作为当前 AI 领域最为火热的前沿趋势之一,可赋能自动驾驶领域的感知、标注、仿真训练等多个核心环节。同时,也可以有效的提升感知精确度,有利于后续规划控制算法的实施,促进端到端自动驾驶框架的发展。

当前智能对话模型的发展中,强大的底层模型起着至关重要的作用。这些先进模型的预训练往往依赖于高质量且多样化的语料库,而如何构建这样的语料库,已成为行业中的一大挑战。

数据获取最新解,便是从生成模型中学习。获取高质量数据,已经成为当前大模型训练的一大瓶颈。

LAMM (Language-Assisted Multi-Modal) 旨在建设面向开源学术社区的多模态指令微调及评测框架,其包括了高度优化的训练框架、全面的评测体系,支持多种视觉模态。

大模型如火如荼发展的一年,也为教育科技带来很大的想象空间。1月5日,国内首个教育智适应多模态大模型发布。大模型革新教育,同样能够做到千人千面,为学生提供个性化的学习服务。