一颗小钢球背后的AI质检革命
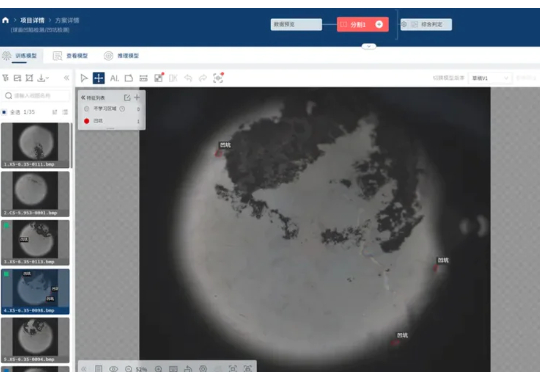
一颗小钢球背后的AI质检革命AI技术应用于小钢球质检,解决人工检测难题:通过视觉系统拍摄清晰图像、训练AI识别微米级缺陷、自动判决。实现从抽检到全检,速度提升100倍至5万颗/小时,准确率达95%,人力成本大幅降。老师傅转变为AI教练,方法可推广至其他领域。
来自主题: AI资讯
10701 点击 2025-09-24 10:50
 搜索
搜索
AI技术应用于小钢球质检,解决人工检测难题:通过视觉系统拍摄清晰图像、训练AI识别微米级缺陷、自动判决。实现从抽检到全检,速度提升100倍至5万颗/小时,准确率达95%,人力成本大幅降。老师傅转变为AI教练,方法可推广至其他领域。

9月17日消息,AI领域的两大巨头Anthropic和OpenAI正致力于开发能够替代人类执行复杂工作的“AI同事”。其核心方法是使用模拟企业软件来训练AI模型,使其能像人类员工那样理解和操作真实的工作流程。
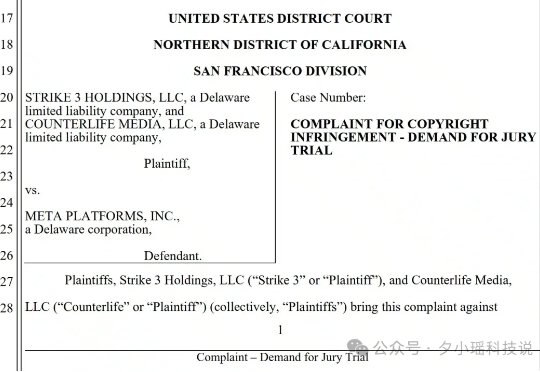
你有没有想过,Meta 训练 AI 用的数据里,有可能不只是维基百科、小说、YouTube 视频……而是你在某个晚上偷偷下载的成人电影? 你没听错。是色情片。而且不是三两个,而是 2396 部!
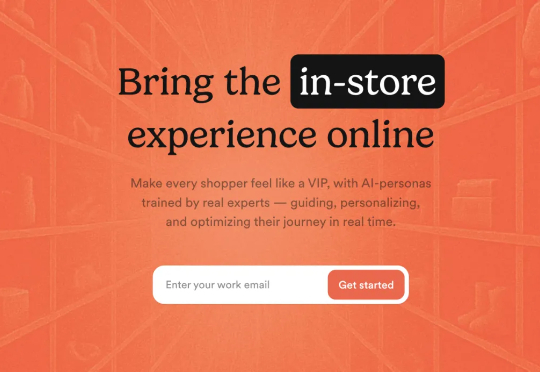
你有没有想过,为什么实体店的转化率能达到30-35%,而在线购物网站却只有可怜的1.5%?

无需原作者同意,AI可以用已出版书籍作训练数据了。
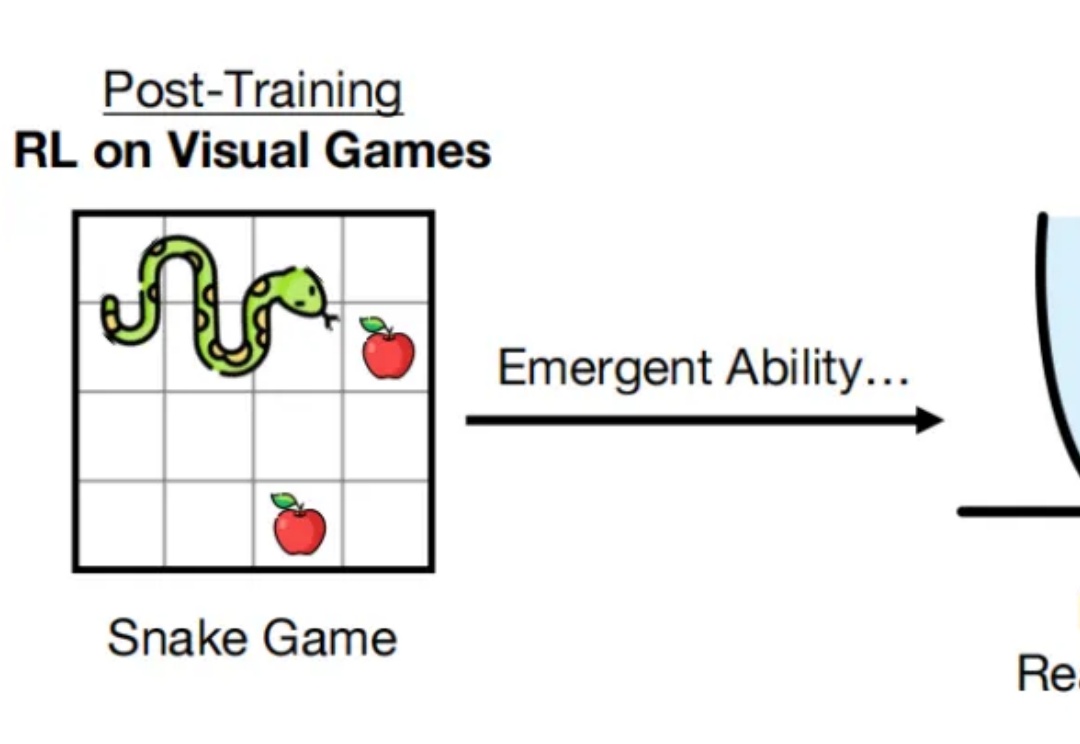
最近,强化学习领域出现了一个颠覆性发现:研究人员不再需要大量数学训练样本,仅仅让 AI 玩简单游戏,就能显著提升其数学推理能力。

第一财经「新皮层」独家获得消息称,小红书已将内部大模型技术与应用产品团队升级为「hi lab」(人文智能实验室,Humane Intelligence Lab)。同时,小红书今年年初开始组建「AI人文训练师」团队,邀请有深厚人文背景的研究者与AI领域的算法工程师、科学家共同完成对AI的后训练,以训练AI具有更好的人文素养以及表现上的一致性。而这个「AI人文训练师」团队也隶属于「hi lab」。

还在用搜索和规则训练AI游戏?现在直接「看回放」学打宝可梦了!德州大学奥斯汀分校的研究团队用Transformer和离线强化学习打造出一个智能体,不靠规则、没用启发式算法,纯靠47.5万场人类对战回放训练出来,居然打上了Pokémon Showdown全球前10%!

最近, Meta首席AI科学家杨立昆接受海外播客This Is IT 的专访,探讨了深度学习的发展历程、机器学习的三种范式、莫拉维克悖论与AI发展的限制、训练AI模型的资源、AI基础设施投资等话题。

近日,IBM宣布了一项重大的光学技术突破,该技术可以以光速训练AI模型,同时节省大量能源。