举报人「自杀」,OpenAI表示震惊!NYU教授发长文悼念:警钟仍在回响
举报人「自杀」,OpenAI表示震惊!NYU教授发长文悼念:警钟仍在回响曾任OpenAI核心研发者的Suchir Balaji,于10月发文直指ChatGPT等生成式AI违背「合理使用」原则。然而,上月底26岁的他被发现离世,疑为自杀。马库斯发文悼念,称Suchir是个勇敢的年轻人,他对AI训练数据的版权问题提出的担忧「切中要害」。
来自主题: AI资讯
6006 点击 2024-12-18 10:47
 搜索
搜索
曾任OpenAI核心研发者的Suchir Balaji,于10月发文直指ChatGPT等生成式AI违背「合理使用」原则。然而,上月底26岁的他被发现离世,疑为自杀。马库斯发文悼念,称Suchir是个勇敢的年轻人,他对AI训练数据的版权问题提出的担忧「切中要害」。

OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。
Show Lab 和微软推出 ShowUI,这是一个刚刚开源的 UI Agent 模型,在中文 APP 定位和导航能力上表现出色。通过创新的视觉 token 选择和独特的训练数据构建方法,该模型在有限的训练数据下实现了非常棒的性能。

谷歌DeepMind最新基础世界模型Genie 2登场!只要一张图,就能生成长达1分钟的游戏世界。从此,我们将拥有无限的具身智能体训练数据。更有人惊呼:黑客帝国来了。
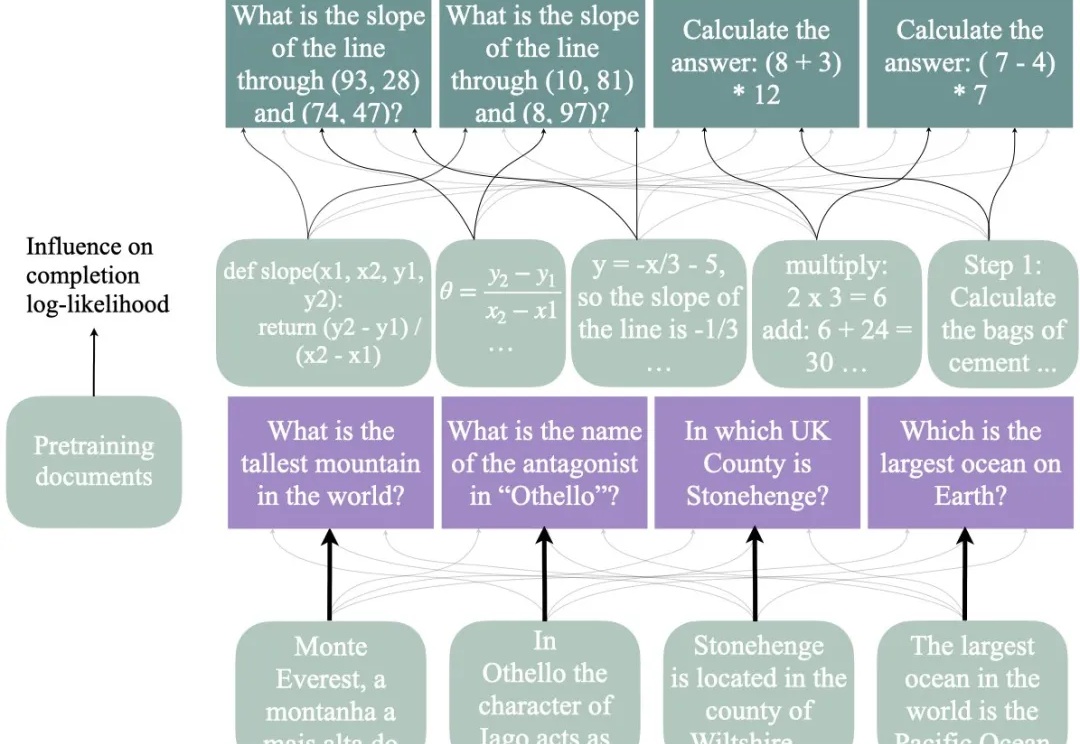
大模型不会照搬训练数据中的数学推理,回答事实问题和推理问题的「思路」也不一样。

最近,Jim Fan参与的一项研究推出了自动化数据生成系统DexMimicGen。该系统可基于少量人类演示,合成类人机器人的灵巧手运动轨迹,解决了训练数据集的获取难题,而且还提升了实验中机器人的表现。

小米大模型第二代来了! 相比第一代,训练数据规模更大、品质更高,训练策略与微调机制上也进行了深入打磨。

去年以来,包括纽约时报、Raw Story、The Intercept和AlterNet等在内的多家机构,针对ChatGPT所属的公司OpenAI提起诉讼,指控ChatGPT非法使用了新闻网站文章用于训练。近日,纽约联邦法官驳回了Raw Story和Alternet对OpenAI聊天机器人的训练数据提起的版权诉讼。

人类只需要演示五次,就能让机器人学会一项复杂技能。英伟达实验室,提出了机器人训练数据缺乏问题的新解决方案——DexMimicGen。

清华大学推出的SonicSim平台和SonicSet数据集针对动态声源的语音处理研究提供了强有力的工具和数据支持,有效降低了数据采集成本,实验证明这些工具能有效提升模型在真实环境中的性能。